A dive into the PE file format - LAB 1: Writing a PE Parser
A dive into the PE file format - LAB 1: Writing a PE Parser
Introduction
In the previous posts we’ve discussed the basic structure of PE files, In this post we’re going to apply this knowledge into building a PE file parser in c++ as a proof of concept.
The parser we’re going to build will not be a full parser and is not intended to be used as a reliable tool, this is only an exercise to better understand the PE file structure.
We’re going to focus on PE32 and PE32+ files, and we’ll only parse the following parts of the file:
- DOS Header
- Rich Header
- NT Headers
- Data Directories (within the Optional Header)
- Section Headers
- Import Table
- Base Relocations Table
The code of this project can be found on my github profile.
Initial Setup
Process Outline
We want out parser to follow the following process:
- Read a file.
- Validate that it’s a PE file.
- Determine whether it’s a
PE32or aPE32+. - Parse out the following structures:
- DOS Header
- Rich Header
- NT Headers
- Section Headers
- Import Data Directory
- Base Relocation Data Directory
- Print out the following information:
- File name and type.
- DOS Header:
- Magic value.
- Address of new exe header.
- Each entry of the Rich Header, decrypted and decoded.
- NT Headers - PE file signature.
- NT Headers - File Header:
- Machine value.
- Number of sections.
- Size of Optional Header.
- NT Headers - Optional Header:
- Magic value.
- Size of code section.
- Size of initialized data.
- Size of uninitialized data.
- Address of entry point.
- RVA of start of code section.
- Desired Image Base.
- Section alignment.
- File alignment.
- Size of image.
- Size of headers.
- For each Data Directory: its name, RVA and size.
- For each Section Header:
- Section name.
- Section virtual address and size.
- Section raw data pointer and size.
- Section characteristics value.
- Import Table:
- For each DLL:
- DLL name.
- ILT and IAT RVAs.
- Whether its a bound import or not.
- for every imported function:
- Ordinal if ordinal/name flag is 1.
- Name, hint and Hint/Name table RVA if ordinal/name flag is 0.
- For each DLL:
- Base Relocation Table:
- For each block:
- Page RVA.
- Block size.
- Number of entries.
- For each entry:
- Raw value.
- Relocation offset.
- Relocation Type.
- For each block:
winnt.h Definitions
We will need the following definitions from the winnt.h header:
- Types:
BYTEWORDDWORDQWORDLONGLONGLONGULONGLONG
- Constants:
IMAGE_NT_OPTIONAL_HDR32_MAGICIMAGE_NT_OPTIONAL_HDR64_MAGICIMAGE_NUMBEROF_DIRECTORY_ENTRIESIMAGE_DOS_SIGNATUREIMAGE_DIRECTORY_ENTRY_EXPORTIMAGE_DIRECTORY_ENTRY_IMPORTIMAGE_DIRECTORY_ENTRY_RESOURCEIMAGE_DIRECTORY_ENTRY_EXCEPTIONIMAGE_DIRECTORY_ENTRY_SECURITYIMAGE_DIRECTORY_ENTRY_BASERELOCIMAGE_DIRECTORY_ENTRY_DEBUGIMAGE_DIRECTORY_ENTRY_ARCHITECTUREIMAGE_DIRECTORY_ENTRY_GLOBALPTRIMAGE_DIRECTORY_ENTRY_TLSIMAGE_DIRECTORY_ENTRY_LOAD_CONFIGIMAGE_DIRECTORY_ENTRY_BOUND_IMPORTIMAGE_DIRECTORY_ENTRY_IATIMAGE_DIRECTORY_ENTRY_DELAY_IMPORTIMAGE_DIRECTORY_ENTRY_COM_DESCRIPTORIMAGE_SIZEOF_SHORT_NAMEIMAGE_SIZEOF_SECTION_HEADER
- Structures:
IMAGE_DOS_HEADERIMAGE_DATA_DIRECTORYIMAGE_OPTIONAL_HEADER32IMAGE_OPTIONAL_HEADER64IMAGE_FILE_HEADERIMAGE_NT_HEADERS32IMAGE_NT_HEADERS64IMAGE_IMPORT_DESCRIPTORIMAGE_IMPORT_BY_NAMEIMAGE_BASE_RELOCATIONIMAGE_SECTION_HEADER
I took these definitions from winnt.h and added them to a new header called winntdef.h.
winntdef.h:
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned long DWORD;
typedef unsigned long long QWORD;
typedef unsigned long LONG;
typedef __int64 LONGLONG;
typedef unsigned __int64 ULONGLONG;
#define ___IMAGE_NT_OPTIONAL_HDR32_MAGIC 0x10b
#define ___IMAGE_NT_OPTIONAL_HDR64_MAGIC 0x20b
#define ___IMAGE_NUMBEROF_DIRECTORY_ENTRIES 16
#define ___IMAGE_DOS_SIGNATURE 0x5A4D
#define ___IMAGE_DIRECTORY_ENTRY_EXPORT 0
#define ___IMAGE_DIRECTORY_ENTRY_IMPORT 1
#define ___IMAGE_DIRECTORY_ENTRY_RESOURCE 2
#define ___IMAGE_DIRECTORY_ENTRY_EXCEPTION 3
#define ___IMAGE_DIRECTORY_ENTRY_SECURITY 4
#define ___IMAGE_DIRECTORY_ENTRY_BASERELOC 5
#define ___IMAGE_DIRECTORY_ENTRY_DEBUG 6
#define ___IMAGE_DIRECTORY_ENTRY_ARCHITECTURE 7
#define ___IMAGE_DIRECTORY_ENTRY_GLOBALPTR 8
#define ___IMAGE_DIRECTORY_ENTRY_TLS 9
#define ___IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG 10
#define ___IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT 11
#define ___IMAGE_DIRECTORY_ENTRY_IAT 12
#define ___IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT 13
#define ___IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR 14
#define ___IMAGE_SIZEOF_SHORT_NAME 8
#define ___IMAGE_SIZEOF_SECTION_HEADER 40
typedef struct __IMAGE_DOS_HEADER {
WORD e_magic;
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
LONG e_lfanew;
} ___IMAGE_DOS_HEADER, * ___PIMAGE_DOS_HEADER;
typedef struct __IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} ___IMAGE_DATA_DIRECTORY, * ___PIMAGE_DATA_DIRECTORY;
typedef struct __IMAGE_OPTIONAL_HEADER {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
___IMAGE_DATA_DIRECTORY DataDirectory[___IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} ___IMAGE_OPTIONAL_HEADER32, * ___PIMAGE_OPTIONAL_HEADER32;
typedef struct __IMAGE_OPTIONAL_HEADER64 {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
ULONGLONG ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
ULONGLONG SizeOfStackReserve;
ULONGLONG SizeOfStackCommit;
ULONGLONG SizeOfHeapReserve;
ULONGLONG SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
___IMAGE_DATA_DIRECTORY DataDirectory[___IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} ___IMAGE_OPTIONAL_HEADER64, * ___PIMAGE_OPTIONAL_HEADER64;
typedef struct __IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} ___IMAGE_FILE_HEADER, * ___PIMAGE_FILE_HEADER;
typedef struct __IMAGE_NT_HEADERS64 {
DWORD Signature;
___IMAGE_FILE_HEADER FileHeader;
___IMAGE_OPTIONAL_HEADER64 OptionalHeader;
} ___IMAGE_NT_HEADERS64, * ___PIMAGE_NT_HEADERS64;
typedef struct __IMAGE_NT_HEADERS {
DWORD Signature;
___IMAGE_FILE_HEADER FileHeader;
___IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} ___IMAGE_NT_HEADERS32, * ___PIMAGE_NT_HEADERS32;
typedef struct __IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics;
DWORD OriginalFirstThunk;
} DUMMYUNIONNAME;
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name;
DWORD FirstThunk;
} ___IMAGE_IMPORT_DESCRIPTOR, * ___PIMAGE_IMPORT_DESCRIPTOR;
typedef struct __IMAGE_IMPORT_BY_NAME {
WORD Hint;
char Name[100];
} ___IMAGE_IMPORT_BY_NAME, * ___PIMAGE_IMPORT_BY_NAME;
typedef struct __IMAGE_BASE_RELOCATION {
DWORD VirtualAddress;
DWORD SizeOfBlock;
} ___IMAGE_BASE_RELOCATION, * ___PIMAGE_BASE_RELOCATION;
typedef struct __IMAGE_SECTION_HEADER {
BYTE Name[___IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} ___IMAGE_SECTION_HEADER, * ___PIMAGE_SECTION_HEADER;
Custom Structures
I defined the following structures to help with the parsing process.
They’re defined in the PEFILE_CUSTOM_STRUCTS.h header.
RICH_HEADER_INFO
A structure to hold information about the Rich Header during processing.
typedef struct __RICH_HEADER_INFO {
int size;
char* ptrToBuffer;
int entries;
} RICH_HEADER_INFO, * PRICH_HEADER_INFO;
-
size: Size of the Rich Header (in bytes). -
ptrToBuffer: A pointer to the buffer containing the data of the Rich Header. -
entries: Number of entries in the Rich Header.
RICH_HEADER_ENTRY
A structure to represent a Rich Header entry.
typedef struct __RICH_HEADER_ENTRY {
WORD prodID;
WORD buildID;
DWORD useCount;
} RICH_HEADER_ENTRY, * PRICH_HEADER_ENTRY;
-
prodID: Type ID / Product ID. -
buildID: Build ID. -
useCount: Use count.
RICH_HEADER
A structure to represent the Rich Header.
typedef struct __RICH_HEADER {
PRICH_HEADER_ENTRY entries;
} RICH_HEADER, * PRICH_HEADER;
-
entries: A pointer to aRICH_HEADER_ENTRYarray.
ILT_ENTRY_32
A structure to represent a 32-bit ILT entry during processing.
typedef struct __ILT_ENTRY_32 {
union {
DWORD ORDINAL : 16;
DWORD HINT_NAME_TABE : 32;
DWORD ORDINAL_NAME_FLAG : 1;
} FIELD_1;
} ILT_ENTRY_32, * PILT_ENTRY_32;
The structure will hold a 32-bit value and will return the appropriate piece of information (using bit fields) when the member corresponding to that piece of information is accessed.
ILT_ENTRY_64
A structure to represent a 64-bit ILT entry during processing.
typedef struct __ILT_ENTRY_64 {
union {
DWORD ORDINAL : 16;
DWORD HINT_NAME_TABE : 32;
} FIELD_2;
DWORD ORDINAL_NAME_FLAG : 1;
} ILT_ENTRY_64, * PILT_ENTRY_64;
The structure will hold a 64-bit value and will return the appropriate piece of information (using bit fields) when the member corresponding to that piece of information is accessed.
BASE_RELOC_ENTRY
A structure to represent a base relocation entry during processing.
typedef struct __BASE_RELOC_ENTRY {
WORD OFFSET : 12;
WORD TYPE : 4;
} BASE_RELOC_ENTRY, * PBASE_RELOC_ENTRY;
-
OFFSET: Relocation offset. -
TYPE: Relocation type.
PEFILE
Our parser will represent a PE file as an object type of either PE32FILE or PE64FILE.
These 2 classes only differ in some member definitions but their functionality is identical.
Throughout this post we will use the code from PE64FILE.
Definition
The class is defined as follows:
class PE64FILE
{
public:
PE64FILE(char* _NAME, FILE* Ppefile);
void PrintInfo();
private:
char* NAME;
FILE* Ppefile;
int _import_directory_count, _import_directory_size;
int _basreloc_directory_count;
// HEADERS
___IMAGE_DOS_HEADER PEFILE_DOS_HEADER;
___IMAGE_NT_HEADERS64 PEFILE_NT_HEADERS;
// DOS HEADER
DWORD PEFILE_DOS_HEADER_EMAGIC;
LONG PEFILE_DOS_HEADER_LFANEW;
// RICH HEADER
RICH_HEADER_INFO PEFILE_RICH_HEADER_INFO;
RICH_HEADER PEFILE_RICH_HEADER;
// NT_HEADERS.Signature
DWORD PEFILE_NT_HEADERS_SIGNATURE;
// NT_HEADERS.FileHeader
WORD PEFILE_NT_HEADERS_FILE_HEADER_MACHINE;
WORD PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS;
WORD PEFILE_NT_HEADERS_FILE_HEADER_SIZEOF_OPTIONAL_HEADER;
// NT_HEADERS.OptionalHeader
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_MAGIC;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_CODE;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_INITIALIZED_DATA;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_UNINITIALIZED_DATA;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_ADDRESSOF_ENTRYPOINT;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_BASEOF_CODE;
ULONGLONG PEFILE_NT_HEADERS_OPTIONAL_HEADER_IMAGEBASE;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_SECTION_ALIGNMENT;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_FILE_ALIGNMENT;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_IMAGE;
DWORD PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_HEADERS;
___IMAGE_DATA_DIRECTORY PEFILE_EXPORT_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_IMPORT_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_RESOURCE_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_EXCEPTION_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_SECURITY_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_BASERELOC_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_DEBUG_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_ARCHITECTURE_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_GLOBALPTR_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_TLS_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_LOAD_CONFIG_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_BOUND_IMPORT_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_IAT_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_DELAY_IMPORT_DIRECTORY;
___IMAGE_DATA_DIRECTORY PEFILE_COM_DESCRIPTOR_DIRECTORY;
// SECTION HEADERS
___PIMAGE_SECTION_HEADER PEFILE_SECTION_HEADERS;
// IMPORT TABLE
___PIMAGE_IMPORT_DESCRIPTOR PEFILE_IMPORT_TABLE;
// BASE RELOCATION TABLE
___PIMAGE_BASE_RELOCATION PEFILE_BASERELOC_TABLE;
// FUNCTIONS
// ADDRESS RESOLVERS
int locate(DWORD VA);
DWORD resolve(DWORD VA, int index);
// PARSERS
void ParseFile();
void ParseDOSHeader();
void ParseNTHeaders();
void ParseSectionHeaders();
void ParseImportDirectory();
void ParseBaseReloc();
void ParseRichHeader();
// PRINT INFO
void PrintFileInfo();
void PrintDOSHeaderInfo();
void PrintRichHeaderInfo();
void PrintNTHeadersInfo();
void PrintSectionHeadersInfo();
void PrintImportTableInfo();
void PrintBaseRelocationsInfo();
};
The only public member beside the class constructor is a function called printInfo() which will print information about the file.
The class constructor takes two parameters, a char array representing the name of the file and a file pointer to the actual data of the file.
After that comes a long series of variables definitions, these class members are going to be used internally during the parsing process and we’ll mention each one of them later.
In the end is a series of methods definitions, first two methods are called locate and resolve, I will talk about them in a minute.
The rest are functions responsible for parsing different parts of the file, and functions responsible for printing information about the same parts.
Constructor
The constructor of the class simply sets the file pointer and name variables, then it calls the ParseFile() function.
PE64FILE::PE64FILE(char* _NAME, FILE* _Ppefile) {
NAME = _NAME;
Ppefile = _Ppefile;
ParseFile();
}
The ParseFile() function calls the other parser functions:
void PE64FILE::ParseFile() {
// PARSE DOS HEADER
ParseDOSHeader();
// PARSE RICH HEADER
ParseRichHeader();
//PARSE NT HEADERS
ParseNTHeaders();
// PARSE SECTION HEADERS
ParseSectionHeaders();
// PARSE IMPORT DIRECTORY
ParseImportDirectory();
// PARSE BASE RELOCATIONS
ParseBaseReloc();
}
Resolving RVAs
Most of the time, we’ll have a RVA that we’ll need to change to a file offset.
The process of resolving an RVA can be outlined as follows:
-
Determine which section range contains that RVA:
- Iterate over all sections and for each section compare the RVA to the section virtual address and to the section virtual address added to the virtual size of the section.
- If the RVA exists within this range then it belongs to that section.
-
Calculate the file offset:
- Subtract the RVA from the section virtual address.
- Add that value to the raw data pointer of the section.
An example of this is locating a Data Directory.
The IMAGE_DATA_DIRECTORY structure only gives us an RVA of the directory, to locate that directory we’ll need to resolve that address.
I wrote two functions to do this, first one to locate the virtual address (locate()), second one to resolve the address (resolve()).
int PE64FILE::locate(DWORD VA) {
int index;
for (int i = 0; i < PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS; i++) {
if (VA >= PEFILE_SECTION_HEADERS[i].VirtualAddress
&& VA < (PEFILE_SECTION_HEADERS[i].VirtualAddress + PEFILE_SECTION_HEADERS[i].Misc.VirtualSize)){
index = i;
break;
}
}
return index;
}
DWORD PE64FILE::resolve(DWORD VA, int index) {
return (VA - PEFILE_SECTION_HEADERS[index].VirtualAddress) + PEFILE_SECTION_HEADERS[index].PointerToRawData;
}
locate() iterates over the PEFILE_SECTION_HEADERS array, compares the RVA as described above, then it returns the index of the appropriate section header within the PEFILE_SECTION_HEADERS array.
Please note that in order for these functions to work we’ll need to parse out the section headers and fill the PEFILE_SECTION_HEADERS array first.
We still haven’t discussed this part, but I wanted to talk about the address resolvers first.
main function
The main function of the program is fairly simple, it only does 2 things:
- Create a file pointer to the given file, and validate that the file was read correctly.
- Call
INITPARSE()on the file, and based on the return value it decides between three actions:- Exit.
- Create a
PE32FILEobject, callPrintInfo(), close the file pointer then exit. - Create a
PE64FILEobject, callPrintInfo(), close the file pointer then exit.
PrintInfo() calls the other print info functions.
int main(int argc, char* argv[])
{
if (argc != 2) {
printf("Usage: %s [path to executable]\n", argv[0]);
return 1;
}
FILE * PpeFile;
fopen_s(&PpeFile, argv[1], "rb");
if (PpeFile == NULL) {
printf("Can't open file.\n");
return 1;
}
if (INITPARSE(PpeFile) == 1) {
exit(1);
}
else if (INITPARSE(PpeFile) == 32) {
PE32FILE PeFile_1(argv[1], PpeFile);
PeFile_1.PrintInfo();
fclose(PpeFile);
exit(0);
}
else if (INITPARSE(PpeFile) == 64) {
PE64FILE PeFile_1(argv[1], PpeFile);
PeFile_1.PrintInfo();
fclose(PpeFile);
exit(0);
}
return 0;
}
INITPARSE()
INITPARSE() is a function defined in PEFILE.cpp.
Its only job is to validate that the given file is a PE file, then determine whether the file is PE32 or PE32+.
It reads the DOS header of the file and checks the DOS MZ header, if not found it returns an error.
After validating the PE file, it sets the file position to (DOS_HEADER.e_lfanew + size of DWORD (PE signature) + size of the file header) which is the exact offset of the beginning of the Optional Header.
Then it reads a WORD, we know that the first WORD of the Optional Header is a magic value that indicates the file type, it then compares that word to IMAGE_NT_OPTIONAL_HDR32_MAGIC and IMAGE_NT_OPTIONAL_HDR64_MAGIC, and based on the comparison results it either returns 32 or 64 indicating PE32 or PE32+, or it returns an error.
int INITPARSE(FILE* PpeFile) {
___IMAGE_DOS_HEADER TMP_DOS_HEADER;
WORD PEFILE_TYPE;
fseek(PpeFile, 0, SEEK_SET);
fread(&TMP_DOS_HEADER, sizeof(___IMAGE_DOS_HEADER), 1, PpeFile);
if (TMP_DOS_HEADER.e_magic != ___IMAGE_DOS_SIGNATURE) {
printf("Error. Not a PE file.\n");
return 1;
}
fseek(PpeFile, (TMP_DOS_HEADER.e_lfanew + sizeof(DWORD) + sizeof(___IMAGE_FILE_HEADER)), SEEK_SET);
fread(&PEFILE_TYPE, sizeof(WORD), 1, PpeFile);
if (PEFILE_TYPE == ___IMAGE_NT_OPTIONAL_HDR32_MAGIC) {
return 32;
}
else if (PEFILE_TYPE == ___IMAGE_NT_OPTIONAL_HDR64_MAGIC) {
return 64;
}
else {
printf("Error while parsing IMAGE_OPTIONAL_HEADER.Magic. Unknown Type.\n");
return 1;
}
}
Parsing DOS Header
ParseDOSHeader()
Parsing out the DOS Header is nothing complicated, we just need to read from the beginning of the file an amount of bytes equal to the size of the DOS Header, then we can assign that data to the pre-defined class member PEFILE_DOS_HEADER.
From there we can access all of the struct members, however we’re only interested in e_magic and e_lfanew.
void PE64FILE::ParseDOSHeader() {
fseek(Ppefile, 0, SEEK_SET);
fread(&PEFILE_DOS_HEADER, sizeof(___IMAGE_DOS_HEADER), 1, Ppefile);
PEFILE_DOS_HEADER_EMAGIC = PEFILE_DOS_HEADER.e_magic;
PEFILE_DOS_HEADER_LFANEW = PEFILE_DOS_HEADER.e_lfanew;
}
PrintDOSHeaderInfo()
This function prints e_magic and e_lfanew values.
void PE64FILE::PrintDOSHeaderInfo() {
printf(" DOS HEADER:\n");
printf(" -----------\n\n");
printf(" Magic: 0x%X\n", PEFILE_DOS_HEADER_EMAGIC);
printf(" File address of new exe header: 0x%X\n", PEFILE_DOS_HEADER_LFANEW);
}

Parsing Rich Header
Process
To parse out the Rich Header we’ll need to go through multiple steps.
We don’t know anything about the Rich Header, we don’t know its size, we don’t know where it’s exactly located, we don’t even know if the file we’re processing contains a Rich Header in the first place.
First of all, we need to locate the Rich Header.
We don’t know the exact location, however we have everything we need to locate it.
We know that if a Rich Header exists, then it has to exist between the DOS Stub and the PE signature or the beginning of the NT Headers.
We also know that any Rich Header ends with a 32-bit value Rich followed by the XOR key.
One might rely on the fixed size of the DOS Header and the DOS Stub, however, the default DOS Stub message can be changed, so that size is not guaranteed to be fixed.
A better approach would be to read from the beginning of the file to the start of the NT Headers, then search through that buffer for the Rich sequence, if found then we’ve successfully located the end of the Rich Header, if not found then most likely the file doesn’t contain a Rich Header.
Once we’ve located the end of the Rich Header, we can read the XOR key, then go backwards starting from the Rich signature and keep XORing 4 bytes at a time until we reach the DanS signature which indicates the beginning of the Rich Header.
After obtaining the position and the size of the Rich Header, we can normally read and process the data.
ParseRichHeader()
This function starts by allocating a buffer on the heap, then it reads e_lfanew size of bytes from the beginning of the file and stores the data in the allocated buffer.
It then goes through a loop where it does a linear search byte by byte. In each iteration it compares the current byte and the byte the follows to 0x52 (R) and 0x69 (i).
When the sequence is found, it stores the index in a variable then the loop breaks.
char* dataPtr = new char[PEFILE_DOS_HEADER_LFANEW];
fseek(Ppefile, 0, SEEK_SET);
fread(dataPtr, PEFILE_DOS_HEADER_LFANEW, 1, Ppefile);
int index_ = 0;
for (int i = 0; i <= PEFILE_DOS_HEADER_LFANEW; i++) {
if (dataPtr[i] == 0x52 && dataPtr[i + 1] == 0x69) {
index_ = i;
break;
}
}
if (index_ == 0) {
printf("Error while parsing Rich Header.");
PEFILE_RICH_HEADER_INFO.entries = 0;
return;
}
After that it reads the XOR key, then goes into the decryption loop where in each iteration it increments RichHeaderSize by 4 until it reaches the DanS sequence.
char key[4];
memcpy(key, dataPtr + (index_ + 4), 4);
int indexpointer = index_ - 4;
int RichHeaderSize = 0;
while (true) {
char tmpchar[4];
memcpy(tmpchar, dataPtr + indexpointer, 4);
for (int i = 0; i < 4; i++) {
tmpchar[i] = tmpchar[i] ^ key[i];
}
indexpointer -= 4;
RichHeaderSize += 4;
if (tmpchar[1] = 0x61 && tmpchar[0] == 0x44) {
break;
}
}
After obtaining the size and the position, it allocates a new buffer for the Rich Header, reads and decrypts the Rich Header, updates PEFILE_RICH_HEADER_INFO with the appropriate data pointer, size and number of entries, then finally it deallocates the buffer it was using for processing.
char* RichHeaderPtr = new char[RichHeaderSize];
memcpy(RichHeaderPtr, dataPtr + (index_ - RichHeaderSize), RichHeaderSize);
for (int i = 0; i < RichHeaderSize; i += 4) {
for (int x = 0; x < 4; x++) {
RichHeaderPtr[i + x] = RichHeaderPtr[i + x] ^ key[x];
}
}
PEFILE_RICH_HEADER_INFO.size = RichHeaderSize;
PEFILE_RICH_HEADER_INFO.ptrToBuffer = RichHeaderPtr;
PEFILE_RICH_HEADER_INFO.entries = (RichHeaderSize - 16) / 8;
delete[] dataPtr;
The rest of the function reads each entry of the Rich Header and updates PEFILE_RICH_HEADER.
PEFILE_RICH_HEADER.entries = new RICH_HEADER_ENTRY[PEFILE_RICH_HEADER_INFO.entries];
for (int i = 16; i < RichHeaderSize; i += 8) {
WORD PRODID = (uint16_t)((unsigned char)RichHeaderPtr[i + 3] << 8) | (unsigned char)RichHeaderPtr[i + 2];
WORD BUILDID = (uint16_t)((unsigned char)RichHeaderPtr[i + 1] << 8) | (unsigned char)RichHeaderPtr[i];
DWORD USECOUNT = (uint32_t)((unsigned char)RichHeaderPtr[i + 7] << 24) | (unsigned char)RichHeaderPtr[i + 6] << 16 | (unsigned char)RichHeaderPtr[i + 5] << 8 | (unsigned char)RichHeaderPtr[i + 4];
PEFILE_RICH_HEADER.entries[(i / 8) - 2] = {
PRODID,
BUILDID,
USECOUNT
};
if (i + 8 >= RichHeaderSize) {
PEFILE_RICH_HEADER.entries[(i / 8) - 1] = { 0x0000, 0x0000, 0x00000000 };
}
}
delete[] PEFILE_RICH_HEADER_INFO.ptrToBuffer;
Here’s the full function:
void PE64FILE::ParseRichHeader() {
char* dataPtr = new char[PEFILE_DOS_HEADER_LFANEW];
fseek(Ppefile, 0, SEEK_SET);
fread(dataPtr, PEFILE_DOS_HEADER_LFANEW, 1, Ppefile);
int index_ = 0;
for (int i = 0; i <= PEFILE_DOS_HEADER_LFANEW; i++) {
if (dataPtr[i] == 0x52 && dataPtr[i + 1] == 0x69) {
index_ = i;
break;
}
}
if (index_ == 0) {
printf("Error while parsing Rich Header.");
PEFILE_RICH_HEADER_INFO.entries = 0;
return;
}
char key[4];
memcpy(key, dataPtr + (index_ + 4), 4);
int indexpointer = index_ - 4;
int RichHeaderSize = 0;
while (true) {
char tmpchar[4];
memcpy(tmpchar, dataPtr + indexpointer, 4);
for (int i = 0; i < 4; i++) {
tmpchar[i] = tmpchar[i] ^ key[i];
}
indexpointer -= 4;
RichHeaderSize += 4;
if (tmpchar[1] = 0x61 && tmpchar[0] == 0x44) {
break;
}
}
char* RichHeaderPtr = new char[RichHeaderSize];
memcpy(RichHeaderPtr, dataPtr + (index_ - RichHeaderSize), RichHeaderSize);
for (int i = 0; i < RichHeaderSize; i += 4) {
for (int x = 0; x < 4; x++) {
RichHeaderPtr[i + x] = RichHeaderPtr[i + x] ^ key[x];
}
}
PEFILE_RICH_HEADER_INFO.size = RichHeaderSize;
PEFILE_RICH_HEADER_INFO.ptrToBuffer = RichHeaderPtr;
PEFILE_RICH_HEADER_INFO.entries = (RichHeaderSize - 16) / 8;
delete[] dataPtr;
PEFILE_RICH_HEADER.entries = new RICH_HEADER_ENTRY[PEFILE_RICH_HEADER_INFO.entries];
for (int i = 16; i < RichHeaderSize; i += 8) {
WORD PRODID = (uint16_t)((unsigned char)RichHeaderPtr[i + 3] << 8) | (unsigned char)RichHeaderPtr[i + 2];
WORD BUILDID = (uint16_t)((unsigned char)RichHeaderPtr[i + 1] << 8) | (unsigned char)RichHeaderPtr[i];
DWORD USECOUNT = (uint32_t)((unsigned char)RichHeaderPtr[i + 7] << 24) | (unsigned char)RichHeaderPtr[i + 6] << 16 | (unsigned char)RichHeaderPtr[i + 5] << 8 | (unsigned char)RichHeaderPtr[i + 4];
PEFILE_RICH_HEADER.entries[(i / 8) - 2] = {
PRODID,
BUILDID,
USECOUNT
};
if (i + 8 >= RichHeaderSize) {
PEFILE_RICH_HEADER.entries[(i / 8) - 1] = { 0x0000, 0x0000, 0x00000000 };
}
}
delete[] PEFILE_RICH_HEADER_INFO.ptrToBuffer;
}
PrintRichHeaderInfo()
This function iterates over each entry in PEFILE_RICH_HEADER and prints its value.
void PE64FILE::PrintRichHeaderInfo() {
printf(" RICH HEADER:\n");
printf(" ------------\n\n");
for (int i = 0; i < PEFILE_RICH_HEADER_INFO.entries; i++) {
printf(" 0x%X 0x%X 0x%X: %d.%d.%d\n",
PEFILE_RICH_HEADER.entries[i].buildID,
PEFILE_RICH_HEADER.entries[i].prodID,
PEFILE_RICH_HEADER.entries[i].useCount,
PEFILE_RICH_HEADER.entries[i].buildID,
PEFILE_RICH_HEADER.entries[i].prodID,
PEFILE_RICH_HEADER.entries[i].useCount);
}
}
Parsing NT Headers
ParseNTHeaders()
Similar to the DOS Header, all we need to do is to read from e_lfanew an amount of bytes equal to the size of IMAGE_NT_HEADERS.
After that we can parse out the contents of the File Header and the Optional Header.
The Optional Header contains an array of IMAGE_DATA_DIRECTORY structures which we care about.
To parse out this information, we can use the IMAGE_DIRECTORY_[...] constants defined in winnt.h as array indexes to access the corresponding IMAGE_DATA_DIRECTORY structure of each Data Directory.
void PE64FILE::ParseNTHeaders() {
fseek(Ppefile, PEFILE_DOS_HEADER.e_lfanew, SEEK_SET);
fread(&PEFILE_NT_HEADERS, sizeof(PEFILE_NT_HEADERS), 1, Ppefile);
PEFILE_NT_HEADERS_SIGNATURE = PEFILE_NT_HEADERS.Signature;
PEFILE_NT_HEADERS_FILE_HEADER_MACHINE = PEFILE_NT_HEADERS.FileHeader.Machine;
PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS = PEFILE_NT_HEADERS.FileHeader.NumberOfSections;
PEFILE_NT_HEADERS_FILE_HEADER_SIZEOF_OPTIONAL_HEADER = PEFILE_NT_HEADERS.FileHeader.SizeOfOptionalHeader;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_MAGIC = PEFILE_NT_HEADERS.OptionalHeader.Magic;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_CODE = PEFILE_NT_HEADERS.OptionalHeader.SizeOfCode;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_INITIALIZED_DATA = PEFILE_NT_HEADERS.OptionalHeader.SizeOfInitializedData;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_UNINITIALIZED_DATA = PEFILE_NT_HEADERS.OptionalHeader.SizeOfUninitializedData;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_ADDRESSOF_ENTRYPOINT = PEFILE_NT_HEADERS.OptionalHeader.AddressOfEntryPoint;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_BASEOF_CODE = PEFILE_NT_HEADERS.OptionalHeader.BaseOfCode;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_IMAGEBASE = PEFILE_NT_HEADERS.OptionalHeader.ImageBase;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_SECTION_ALIGNMENT = PEFILE_NT_HEADERS.OptionalHeader.SectionAlignment;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_FILE_ALIGNMENT = PEFILE_NT_HEADERS.OptionalHeader.FileAlignment;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_IMAGE = PEFILE_NT_HEADERS.OptionalHeader.SizeOfImage;
PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_HEADERS = PEFILE_NT_HEADERS.OptionalHeader.SizeOfHeaders;
PEFILE_EXPORT_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_EXPORT];
PEFILE_IMPORT_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_IMPORT];
PEFILE_RESOURCE_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_RESOURCE];
PEFILE_EXCEPTION_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_EXCEPTION];
PEFILE_SECURITY_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_SECURITY];
PEFILE_BASERELOC_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_BASERELOC];
PEFILE_DEBUG_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_DEBUG];
PEFILE_ARCHITECTURE_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_ARCHITECTURE];
PEFILE_GLOBALPTR_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_GLOBALPTR];
PEFILE_TLS_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_TLS];
PEFILE_LOAD_CONFIG_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG];
PEFILE_BOUND_IMPORT_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT];
PEFILE_IAT_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_IAT];
PEFILE_DELAY_IMPORT_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT];
PEFILE_COM_DESCRIPTOR_DIRECTORY = PEFILE_NT_HEADERS.OptionalHeader.DataDirectory[___IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR];
}
PrintNTHeadersInfo()
This function prints the data obtained from the File Header and the Optional Header, and for each Data Directory it prints its RVA and size.
void PE64FILE::PrintNTHeadersInfo() {
printf(" NT HEADERS:\n");
printf(" -----------\n\n");
printf(" PE Signature: 0x%X\n", PEFILE_NT_HEADERS_SIGNATURE);
printf("\n File Header:\n\n");
printf(" Machine: 0x%X\n", PEFILE_NT_HEADERS_FILE_HEADER_MACHINE);
printf(" Number of sections: 0x%X\n", PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS);
printf(" Size of optional header: 0x%X\n", PEFILE_NT_HEADERS_FILE_HEADER_SIZEOF_OPTIONAL_HEADER);
printf("\n Optional Header:\n\n");
printf(" Magic: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_MAGIC);
printf(" Size of code section: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_CODE);
printf(" Size of initialized data: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_INITIALIZED_DATA);
printf(" Size of uninitialized data: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_UNINITIALIZED_DATA);
printf(" Address of entry point: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_ADDRESSOF_ENTRYPOINT);
printf(" RVA of start of code section: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_BASEOF_CODE);
printf(" Desired image base: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_IMAGEBASE);
printf(" Section alignment: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_SECTION_ALIGNMENT);
printf(" File alignment: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_FILE_ALIGNMENT);
printf(" Size of image: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_IMAGE);
printf(" Size of headers: 0x%X\n", PEFILE_NT_HEADERS_OPTIONAL_HEADER_SIZEOF_HEADERS);
printf("\n Data Directories:\n");
printf("\n * Export Directory:\n");
printf(" RVA: 0x%X\n", PEFILE_EXPORT_DIRECTORY.VirtualAddress);
printf(" Size: 0x%X\n", PEFILE_EXPORT_DIRECTORY.Size);
.
.
[REDACTED]
.
.
printf("\n * COM Runtime Descriptor:\n");
printf(" RVA: 0x%X\n", PEFILE_COM_DESCRIPTOR_DIRECTORY.VirtualAddress);
printf(" Size: 0x%X\n", PEFILE_COM_DESCRIPTOR_DIRECTORY.Size);
}
Parsing Section Headers
ParseSectionHeaders()
This function starts by assigning the PEFILE_SECTION_HEADERS class member to a pointer to an IMAGE_SECTION_HEADER array of the count of PEFILE_NT_HEADERS_FILE_HEADER_NUMBEROF_SECTIONS.
Then it goes into a loop of PEFILE_NT_HEADERS_FILE_HEADER_NUMBEROF_SECTIONS iterations where in each iteration it changes the file offset to (e_lfanew + size of NT Headers + loop counter multiplied by the size of a section header) to reach the beginning of the next Section Header, then it reads the new Section Header and assigns it to the next element of PEFILE_SECTION_HEADERS.
void PE64FILE::ParseSectionHeaders() {
PEFILE_SECTION_HEADERS = new ___IMAGE_SECTION_HEADER[PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS];
for (int i = 0; i < PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS; i++) {
int offset = (PEFILE_DOS_HEADER.e_lfanew + sizeof(PEFILE_NT_HEADERS)) + (i * ___IMAGE_SIZEOF_SECTION_HEADER);
fseek(Ppefile, offset, SEEK_SET);
fread(&PEFILE_SECTION_HEADERS[i], ___IMAGE_SIZEOF_SECTION_HEADER, 1, Ppefile);
}
}
PrintSectionHeadersInfo()
This function loops over the Section Headers array (filled by ParseSectionHeaders()), and it prints information about each section.
void PE64FILE::PrintSectionHeadersInfo() {
printf(" SECTION HEADERS:\n");
printf(" ----------------\n\n");
for (int i = 0; i < PEFILE_NT_HEADERS_FILE_HEADER_NUMBER0F_SECTIONS; i++) {
printf(" * %.8s:\n", PEFILE_SECTION_HEADERS[i].Name);
printf(" VirtualAddress: 0x%X\n", PEFILE_SECTION_HEADERS[i].VirtualAddress);
printf(" VirtualSize: 0x%X\n", PEFILE_SECTION_HEADERS[i].Misc.VirtualSize);
printf(" PointerToRawData: 0x%X\n", PEFILE_SECTION_HEADERS[i].PointerToRawData);
printf(" SizeOfRawData: 0x%X\n", PEFILE_SECTION_HEADERS[i].SizeOfRawData);
printf(" Characteristics: 0x%X\n\n", PEFILE_SECTION_HEADERS[i].Characteristics);
}
}
Parsing Imports
ParseImportDirectory()
To parse out the Import Directory Table we need to determine the count of IMAGE_IMPORT_DESCRIPTORs first.
This function starts by resolving the file offset of the Import Directory, then it goes into a loop where in each loop it keeps reading the next import descriptor.
In each iteration it checks if the descriptor has zeroed out values, if that is the case then we’ve reached the end of the Import Directory, so it breaks.
Otherwise it increments _import_directory_count and the loop continues.
After finding the size of the Import Directory, the function assigns the PEFILE_IMPORT_TABLE class member to a pointer to an IMAGE_IMPORT_DESCRIPTOR array of the count of _import_directory_count then goes into another loop similar to the one we’ve seen in ParseSectionHeaders() to parse out the import descriptors.
void PE64FILE::ParseImportDirectory() {
DWORD _import_directory_address = resolve(PEFILE_IMPORT_DIRECTORY.VirtualAddress, locate(PEFILE_IMPORT_DIRECTORY.VirtualAddress));
_import_directory_count = 0;
while (true) {
___IMAGE_IMPORT_DESCRIPTOR tmp;
int offset = (_import_directory_count * sizeof(___IMAGE_IMPORT_DESCRIPTOR)) + _import_directory_address;
fseek(Ppefile, offset, SEEK_SET);
fread(&tmp, sizeof(___IMAGE_IMPORT_DESCRIPTOR), 1, Ppefile);
if (tmp.Name == 0x00000000 && tmp.FirstThunk == 0x00000000) {
_import_directory_count -= 1;
_import_directory_size = _import_directory_count * sizeof(___IMAGE_IMPORT_DESCRIPTOR);
break;
}
_import_directory_count++;
}
PEFILE_IMPORT_TABLE = new ___IMAGE_IMPORT_DESCRIPTOR[_import_directory_count];
for (int i = 0; i < _import_directory_count; i++) {
int offset = (i * sizeof(___IMAGE_IMPORT_DESCRIPTOR)) + _import_directory_address;
fseek(Ppefile, offset, SEEK_SET);
fread(&PEFILE_IMPORT_TABLE[i], sizeof(___IMAGE_IMPORT_DESCRIPTOR), 1, Ppefile);
}
}
PrintImportTableInfo()
After obtaining the import descriptors, further parsing is needed to retrieve information about the imported functions.
This is done by the PrintImportTableInfo() function.
This function iterates over the import descriptors, and for each descriptor it resolves the file offset of the DLL name, retrieves the DLL name then prints it, it also prints the ILT RVA, the IAT RVA and whether the import is bound or not.
After that it resolves the file offset of the ILT then it parses out each ILT entry.
If the Ordinal/Name flag is set it prints the function ordinal, otherwise it prints the function name, the hint RVA and the hint.
If the ILT entry is zeroed out, the loop breaks and the next import descriptor parsing iteration starts.
We’ve discussed the details about this in the PE imports post.
void PE64FILE::PrintImportTableInfo() {
printf(" IMPORT TABLE:\n");
printf(" ----------------\n\n");
for (int i = 0; i < _import_directory_count; i++) {
DWORD NameAddr = resolve(PEFILE_IMPORT_TABLE[i].Name, locate(PEFILE_IMPORT_TABLE[i].Name));
int NameSize = 0;
while (true) {
char tmp;
fseek(Ppefile, (NameAddr + NameSize), SEEK_SET);
fread(&tmp, sizeof(char), 1, Ppefile);
if (tmp == 0x00) {
break;
}
NameSize++;
}
char* Name = new char[NameSize + 2];
fseek(Ppefile, NameAddr, SEEK_SET);
fread(Name, (NameSize * sizeof(char)) + 1, 1, Ppefile);
printf(" * %s:\n", Name);
delete[] Name;
printf(" ILT RVA: 0x%X\n", PEFILE_IMPORT_TABLE[i].DUMMYUNIONNAME.OriginalFirstThunk);
printf(" IAT RVA: 0x%X\n", PEFILE_IMPORT_TABLE[i].FirstThunk);
if (PEFILE_IMPORT_TABLE[i].TimeDateStamp == 0) {
printf(" Bound: FALSE\n");
}
else if (PEFILE_IMPORT_TABLE[i].TimeDateStamp == -1) {
printf(" Bound: TRUE\n");
}
printf("\n");
DWORD ILTAddr = resolve(PEFILE_IMPORT_TABLE[i].DUMMYUNIONNAME.OriginalFirstThunk, locate(PEFILE_IMPORT_TABLE[i].DUMMYUNIONNAME.OriginalFirstThunk));
int entrycounter = 0;
while (true) {
ILT_ENTRY_64 entry;
fseek(Ppefile, (ILTAddr + (entrycounter * sizeof(QWORD))), SEEK_SET);
fread(&entry, sizeof(ILT_ENTRY_64), 1, Ppefile);
BYTE flag = entry.ORDINAL_NAME_FLAG;
DWORD HintRVA = 0x0;
WORD ordinal = 0x0;
if (flag == 0x0) {
HintRVA = entry.FIELD_2.HINT_NAME_TABE;
}
else if (flag == 0x01) {
ordinal = entry.FIELD_2.ORDINAL;
}
if (flag == 0x0 && HintRVA == 0x0 && ordinal == 0x0) {
break;
}
printf("\n Entry:\n");
if (flag == 0x0) {
___IMAGE_IMPORT_BY_NAME hint;
DWORD HintAddr = resolve(HintRVA, locate(HintRVA));
fseek(Ppefile, HintAddr, SEEK_SET);
fread(&hint, sizeof(___IMAGE_IMPORT_BY_NAME), 1, Ppefile);
printf(" Name: %s\n", hint.Name);
printf(" Hint RVA: 0x%X\n", HintRVA);
printf(" Hint: 0x%X\n", hint.Hint);
}
else if (flag == 1) {
printf(" Ordinal: 0x%X\n", ordinal);
}
entrycounter++;
}
printf("\n ----------------------\n\n");
}
}
Parsing Base Relocations
ParseBaseReloc()
This function follows the same process we’ve seen in ParseImportDirectory().
It resolves the file offset of the Base Relocation Directory, then it loops over each relocation block until it reaches a zeroed out block. Then it parses out these blocks and saves each IMAGE_BASE_RELOCATION structure in PEFILE_BASERELOC_TABLE.
One thing to note here that is different from what we’ve seen in ParseImportDirectory() is that in addition to keeping a block counter we also keep a size counter that’s incremented by adding the value of SizeOfBlock of each block in each iteration.
We do this because relocation blocks don’t have a fixed size, and in order to correctly calculate the offset of the next relocation block we need the total size of the previous blocks.
void PE64FILE::ParseBaseReloc() {
DWORD _basereloc_directory_address = resolve(PEFILE_BASERELOC_DIRECTORY.VirtualAddress, locate(PEFILE_BASERELOC_DIRECTORY.VirtualAddress));
_basreloc_directory_count = 0;
int _basereloc_size_counter = 0;
while (true) {
___IMAGE_BASE_RELOCATION tmp;
int offset = (_basereloc_size_counter + _basereloc_directory_address);
fseek(Ppefile, offset, SEEK_SET);
fread(&tmp, sizeof(___IMAGE_BASE_RELOCATION), 1, Ppefile);
if (tmp.VirtualAddress == 0x00000000 &&
tmp.SizeOfBlock == 0x00000000) {
break;
}
_basreloc_directory_count++;
_basereloc_size_counter += tmp.SizeOfBlock;
}
PEFILE_BASERELOC_TABLE = new ___IMAGE_BASE_RELOCATION[_basreloc_directory_count];
_basereloc_size_counter = 0;
for (int i = 0; i < _basreloc_directory_count; i++) {
int offset = _basereloc_directory_address + _basereloc_size_counter;
fseek(Ppefile, offset, SEEK_SET);
fread(&PEFILE_BASERELOC_TABLE[i], sizeof(___IMAGE_BASE_RELOCATION), 1, Ppefile);
_basereloc_size_counter += PEFILE_BASERELOC_TABLE[i].SizeOfBlock;
}
}
PrintBaseRelocationInfo()
This function iterates over the base relocation blocks, and for each block it resolves the file offset of the block, then it prints the block RVA, size and number of entries (calculated by subtracting the size of IMAGE_BASE_RELOCATION from the block size then dividing that by the size of a WORD).
After that it iterates over the relocation entries and prints the relocation value, and from that value it separates the type and the offset and prints each one of them.
We’ve discussed the details about this in the PE base relocations post.
void PE64FILE::PrintBaseRelocationsInfo() {
printf(" BASE RELOCATIONS TABLE:\n");
printf(" -----------------------\n");
int szCounter = sizeof(___IMAGE_BASE_RELOCATION);
for (int i = 0; i < _basreloc_directory_count; i++) {
DWORD PAGERVA, BLOCKSIZE, BASE_RELOC_ADDR;
int ENTRIES;
BASE_RELOC_ADDR = resolve(PEFILE_BASERELOC_DIRECTORY.VirtualAddress, locate(PEFILE_BASERELOC_DIRECTORY.VirtualAddress));
PAGERVA = PEFILE_BASERELOC_TABLE[i].VirtualAddress;
BLOCKSIZE = PEFILE_BASERELOC_TABLE[i].SizeOfBlock;
ENTRIES = (BLOCKSIZE - sizeof(___IMAGE_BASE_RELOCATION)) / sizeof(WORD);
printf("\n Block 0x%X: \n", i);
printf(" Page RVA: 0x%X\n", PAGERVA);
printf(" Block size: 0x%X\n", BLOCKSIZE);
printf(" Number of entries: 0x%X\n", ENTRIES);
printf("\n Entries:\n");
for (int i = 0; i < ENTRIES; i++) {
BASE_RELOC_ENTRY entry;
int offset = (BASE_RELOC_ADDR + szCounter + (i * sizeof(WORD)));
fseek(Ppefile, offset, SEEK_SET);
fread(&entry, sizeof(WORD), 1, Ppefile);
printf("\n * Value: 0x%X\n", entry);
printf(" Relocation Type: 0x%X\n", entry.TYPE);
printf(" Offset: 0x%X\n", entry.OFFSET);
}
printf("\n ----------------------\n\n");
szCounter += BLOCKSIZE;
}
}
Conclusion
Here’s the full output after running the parser on a file:
Desktop>.\PE-Parser.exe .\SimpleApp64.exe
FILE: .\SimpleApp64.exe
TYPE: 0x20B (PE32+)
----------------------------------
DOS HEADER:
-----------
Magic: 0x5A4D
File address of new exe header: 0x100
----------------------------------
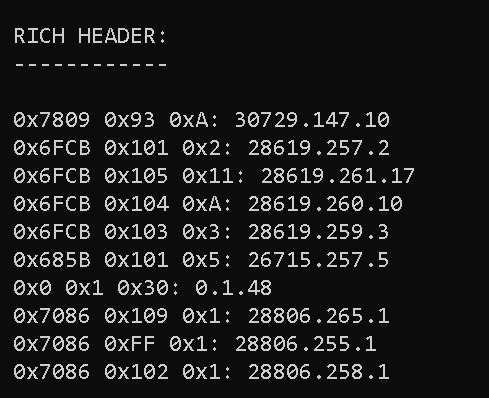
RICH HEADER:
------------
0x7809 0x93 0xA: 30729.147.10
0x6FCB 0x101 0x2: 28619.257.2
0x6FCB 0x105 0x11: 28619.261.17
0x6FCB 0x104 0xA: 28619.260.10
0x6FCB 0x103 0x3: 28619.259.3
0x685B 0x101 0x5: 26715.257.5
0x0 0x1 0x30: 0.1.48
0x7086 0x109 0x1: 28806.265.1
0x7086 0xFF 0x1: 28806.255.1
0x7086 0x102 0x1: 28806.258.1
----------------------------------
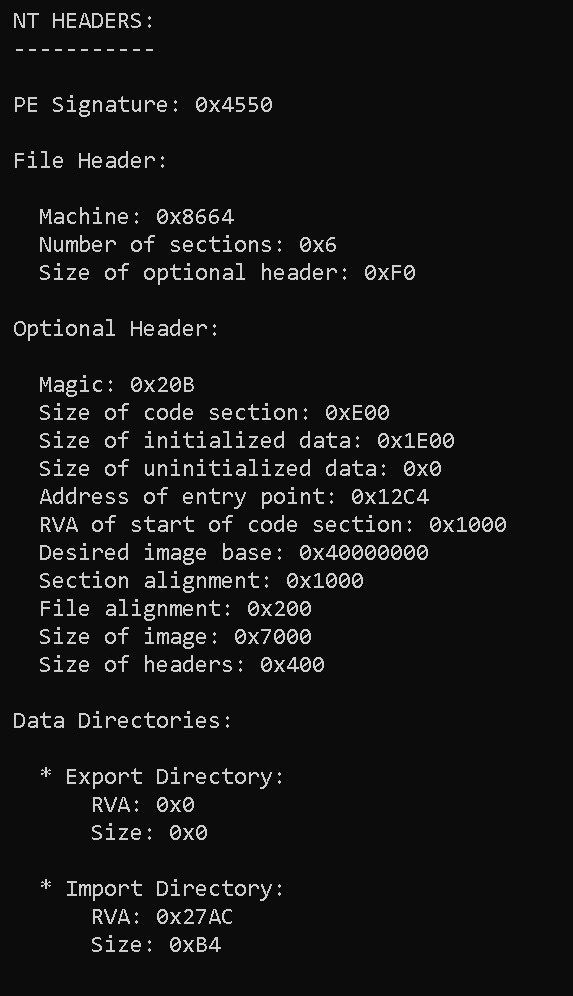
NT HEADERS:
-----------
PE Signature: 0x4550
File Header:
Machine: 0x8664
Number of sections: 0x6
Size of optional header: 0xF0
Optional Header:
Magic: 0x20B
Size of code section: 0xE00
Size of initialized data: 0x1E00
Size of uninitialized data: 0x0
Address of entry point: 0x12C4
RVA of start of code section: 0x1000
Desired image base: 0x40000000
Section alignment: 0x1000
File alignment: 0x200
Size of image: 0x7000
Size of headers: 0x400
Data Directories:
* Export Directory:
RVA: 0x0
Size: 0x0
* Import Directory:
RVA: 0x27AC
Size: 0xB4
* Resource Directory:
RVA: 0x5000
Size: 0x1E0
* Exception Directory:
RVA: 0x4000
Size: 0x168
* Security Directory:
RVA: 0x0
Size: 0x0
* Base Relocation Table:
RVA: 0x6000
Size: 0x28
* Debug Directory:
RVA: 0x2248
Size: 0x70
* Architecture Specific Data:
RVA: 0x0
Size: 0x0
* RVA of GlobalPtr:
RVA: 0x0
Size: 0x0
* TLS Directory:
RVA: 0x0
Size: 0x0
* Load Configuration Directory:
RVA: 0x22C0
Size: 0x130
* Bound Import Directory:
RVA: 0x0
Size: 0x0
* Import Address Table:
RVA: 0x2000
Size: 0x198
* Delay Load Import Descriptors:
RVA: 0x0
Size: 0x0
* COM Runtime Descriptor:
RVA: 0x0
Size: 0x0
----------------------------------
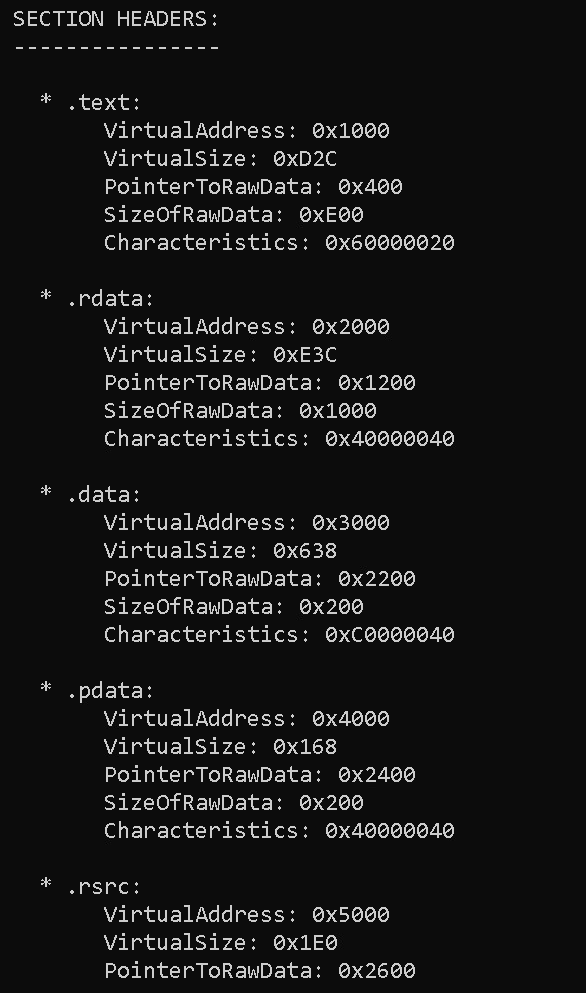
SECTION HEADERS:
----------------
* .text:
VirtualAddress: 0x1000
VirtualSize: 0xD2C
PointerToRawData: 0x400
SizeOfRawData: 0xE00
Characteristics: 0x60000020
* .rdata:
VirtualAddress: 0x2000
VirtualSize: 0xE3C
PointerToRawData: 0x1200
SizeOfRawData: 0x1000
Characteristics: 0x40000040
* .data:
VirtualAddress: 0x3000
VirtualSize: 0x638
PointerToRawData: 0x2200
SizeOfRawData: 0x200
Characteristics: 0xC0000040
* .pdata:
VirtualAddress: 0x4000
VirtualSize: 0x168
PointerToRawData: 0x2400
SizeOfRawData: 0x200
Characteristics: 0x40000040
* .rsrc:
VirtualAddress: 0x5000
VirtualSize: 0x1E0
PointerToRawData: 0x2600
SizeOfRawData: 0x200
Characteristics: 0x40000040
* .reloc:
VirtualAddress: 0x6000
VirtualSize: 0x28
PointerToRawData: 0x2800
SizeOfRawData: 0x200
Characteristics: 0x42000040
----------------------------------
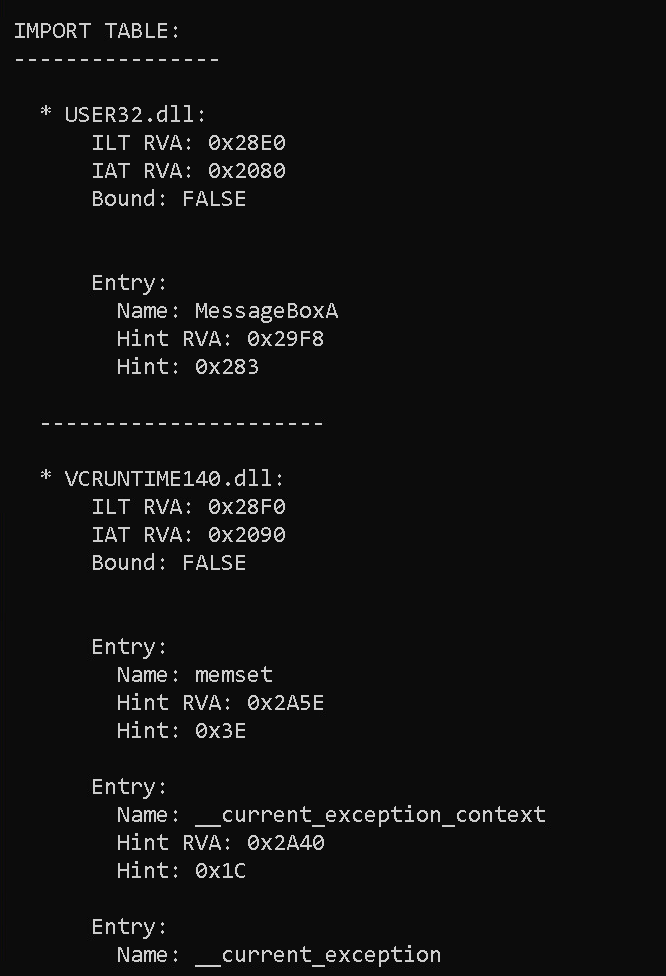
IMPORT TABLE:
----------------
* USER32.dll:
ILT RVA: 0x28E0
IAT RVA: 0x2080
Bound: FALSE
Entry:
Name: MessageBoxA
Hint RVA: 0x29F8
Hint: 0x283
----------------------
* VCRUNTIME140.dll:
ILT RVA: 0x28F0
IAT RVA: 0x2090
Bound: FALSE
Entry:
Name: memset
Hint RVA: 0x2A5E
Hint: 0x3E
Entry:
Name: __current_exception_context
Hint RVA: 0x2A40
Hint: 0x1C
Entry:
Name: __current_exception
Hint RVA: 0x2A2A
Hint: 0x1B
Entry:
Name: __C_specific_handler
Hint RVA: 0x2A12
Hint: 0x8
----------------------
* api-ms-win-crt-runtime-l1-1-0.dll:
ILT RVA: 0x2948
IAT RVA: 0x20E8
Bound: FALSE
Entry:
Name: _crt_atexit
Hint RVA: 0x2C12
Hint: 0x1E
Entry:
Name: terminate
Hint RVA: 0x2C20
Hint: 0x67
Entry:
Name: _exit
Hint RVA: 0x2B30
Hint: 0x23
Entry:
Name: _register_thread_local_exe_atexit_callback
Hint RVA: 0x2B76
Hint: 0x3D
Entry:
Name: _c_exit
Hint RVA: 0x2B6C
Hint: 0x15
Entry:
Name: exit
Hint RVA: 0x2B28
Hint: 0x55
Entry:
Name: _initterm_e
Hint RVA: 0x2B1A
Hint: 0x37
Entry:
Name: _initterm
Hint RVA: 0x2B0E
Hint: 0x36
Entry:
Name: _get_initial_narrow_environment
Hint RVA: 0x2AEC
Hint: 0x28
Entry:
Name: _initialize_narrow_environment
Hint RVA: 0x2ACA
Hint: 0x33
Entry:
Name: _configure_narrow_argv
Hint RVA: 0x2AB0
Hint: 0x18
Entry:
Name: _initialize_onexit_table
Hint RVA: 0x2BDA
Hint: 0x34
Entry:
Name: _set_app_type
Hint RVA: 0x2A8C
Hint: 0x42
Entry:
Name: _seh_filter_exe
Hint RVA: 0x2A7A
Hint: 0x40
Entry:
Name: _cexit
Hint RVA: 0x2B62
Hint: 0x16
Entry:
Name: __p___argv
Hint RVA: 0x2B54
Hint: 0x5
Entry:
Name: __p___argc
Hint RVA: 0x2B46
Hint: 0x4
Entry:
Name: _register_onexit_function
Hint RVA: 0x2BF6
Hint: 0x3C
----------------------
* api-ms-win-crt-math-l1-1-0.dll:
ILT RVA: 0x2938
IAT RVA: 0x20D8
Bound: FALSE
Entry:
Name: __setusermatherr
Hint RVA: 0x2A9C
Hint: 0x9
----------------------
* api-ms-win-crt-stdio-l1-1-0.dll:
ILT RVA: 0x29E0
IAT RVA: 0x2180
Bound: FALSE
Entry:
Name: __p__commode
Hint RVA: 0x2BCA
Hint: 0x1
Entry:
Name: _set_fmode
Hint RVA: 0x2B38
Hint: 0x54
----------------------
* api-ms-win-crt-locale-l1-1-0.dll:
ILT RVA: 0x2928
IAT RVA: 0x20C8
Bound: FALSE
Entry:
Name: _configthreadlocale
Hint RVA: 0x2BA4
Hint: 0x8
----------------------
* api-ms-win-crt-heap-l1-1-0.dll:
ILT RVA: 0x2918
IAT RVA: 0x20B8
Bound: FALSE
Entry:
Name: _set_new_mode
Hint RVA: 0x2BBA
Hint: 0x16
----------------------
----------------------------------
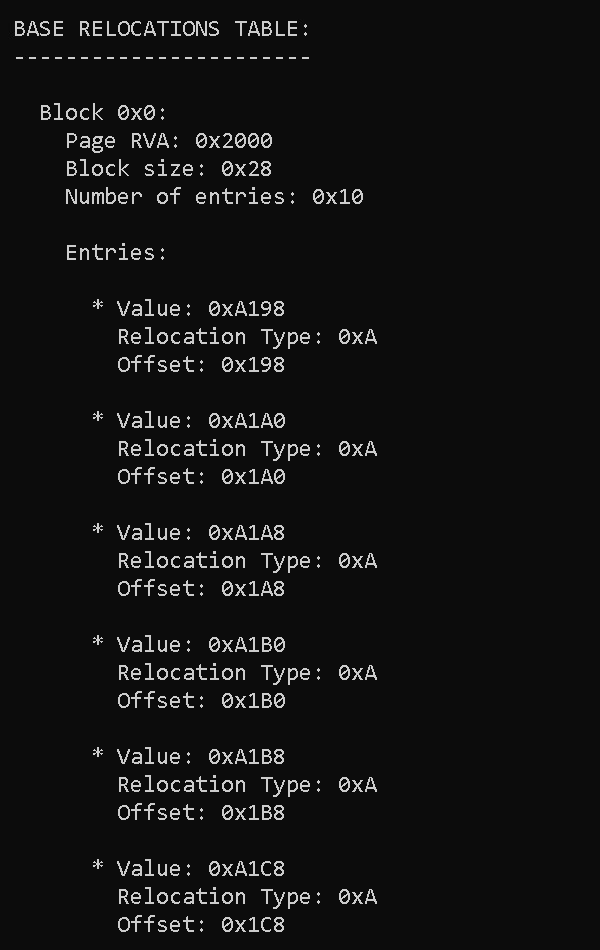
BASE RELOCATIONS TABLE:
-----------------------
Block 0x0:
Page RVA: 0x2000
Block size: 0x28
Number of entries: 0x10
Entries:
* Value: 0xA198
Relocation Type: 0xA
Offset: 0x198
* Value: 0xA1A0
Relocation Type: 0xA
Offset: 0x1A0
* Value: 0xA1A8
Relocation Type: 0xA
Offset: 0x1A8
* Value: 0xA1B0
Relocation Type: 0xA
Offset: 0x1B0
* Value: 0xA1B8
Relocation Type: 0xA
Offset: 0x1B8
* Value: 0xA1C8
Relocation Type: 0xA
Offset: 0x1C8
* Value: 0xA1E0
Relocation Type: 0xA
Offset: 0x1E0
* Value: 0xA1E8
Relocation Type: 0xA
Offset: 0x1E8
* Value: 0xA220
Relocation Type: 0xA
Offset: 0x220
* Value: 0xA228
Relocation Type: 0xA
Offset: 0x228
* Value: 0xA318
Relocation Type: 0xA
Offset: 0x318
* Value: 0xA330
Relocation Type: 0xA
Offset: 0x330
* Value: 0xA338
Relocation Type: 0xA
Offset: 0x338
* Value: 0xA3D8
Relocation Type: 0xA
Offset: 0x3D8
* Value: 0xA3E0
Relocation Type: 0xA
Offset: 0x3E0
* Value: 0xA3E8
Relocation Type: 0xA
Offset: 0x3E8
----------------------
----------------------------------
I hope that seeing actual code has given you a better understanding of what we’ve discussed throughout the previous posts.
I believe that there are better ways for implementation than the ones I have presented, I’m in no way a c++ programmer and I know that there’s always room for improvement, so feel free to reach out to me, any feedback would be much appreciated.
Thanks for reading.