A dive into the PE file format - PE file structure - Part 2: DOS Header, DOS Stub and Rich Header
A dive into the PE file format - PE file structure - Part 2: DOS Header, DOS Stub and Rich Header
Introduction
In the previous post we looked at a high level overview of the PE file structure, in this post we’re going to talk about the first two parts which are the DOS Header and the DOS Stub.
The PE viewer I’m going to use throughout the series is called PE-bear, it’s full of features and has a good UI.
DOS Header
Overview
The DOS header (also called the MS-DOS header) is a 64-byte-long structure that exists at the start of the PE file.
it’s not important for the functionality of PE files on modern Windows systems, however it’s there because of backward compatibility reasons.
This header makes the file an MS-DOS executable, so when it’s loaded on MS-DOS the DOS stub gets executed instead of the actual program.
Without this header, if you attempt to load the executable on MS-DOS it will not be loaded and will just produce a generic error.
Structure
As mentioned before, it’s a 64-byte-long structure, we can take a look at the contents of that structure by looking at the IMAGE_DOS_HEADER structure definition from winnt.h:
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
This structure is important to the PE loader on MS-DOS, however only a few members of it are important to the PE loader on Windows Systems, so we’re not going to cover everything in here, just the important members of the structure.
-
e_magic: This is the first member of the DOS Header, it’s a WORD so it occupies 2 bytes, it’s usually called the magic number. It has a fixed value of0x5A4DorMZin ASCII, and it serves as a signature that marks the file as an MS-DOS executable. -
e_lfanew: This is the last member of the DOS header structure, it’s located at offset0x3Cinto the DOS header and it holds an offset to the start of the NT headers. This member is important to the PE loader on Windows systems because it tells the loader where to look for the file header.
The following picture shows contents of the DOS header in an actual PE file using PE-bear:
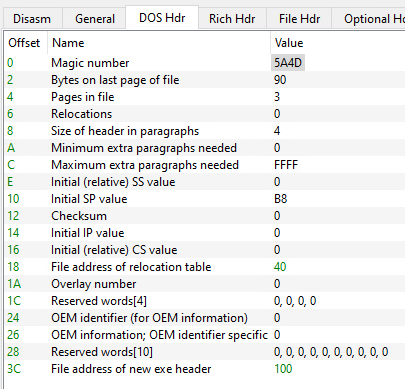
As you can see, the first member of the header is the magic number with the fixed value we talked about which was 5A4D.
The last member of the header (at offset 0x3C) is given the name “File address of new exe header”, it has the value 100, we can follow to that offset and we’ll find the start of the NT headers as expected:

DOS Stub
Overview
The DOS stub is an MS-DOS program that prints an error message saying that the executable is not compatible with DOS then exits.
This is what gets executed when the program is loaded in MS-DOS, the default error message is “This program cannot be run in DOS mode.”, however this message can be changed by the user during compile time.
That’s all we need to know about the DOS stub, we don’t really care about it, but let’s take a look at what it’s doing just for fun.
Analysis
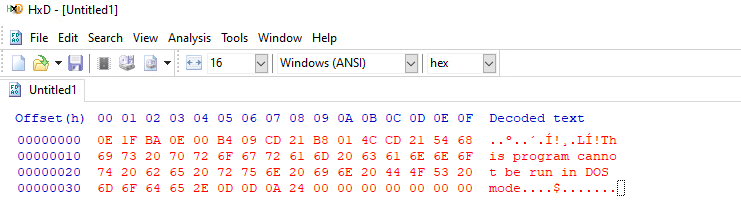
To be able to disassemble the machine code of the DOS stub, I copied the code of the stub from PE-bear, then I created a new file with the stub contents using a hex editor (HxD) and gave it the name dos-stub.exe.
Stub code:
0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 54 68
69 73 20 70 72 6F 67 72 61 6D 20 63 61 6E 6E 6F
74 20 62 65 20 72 75 6E 20 69 6E 20 44 4F 53 20
6D 6F 64 65 2E 0D 0D 0A 24 00 00 00 00 00 00 00

After that I used IDA to disassemble the executable, MS-DOS programs are 16-bit programs, so I chose the intel 8086 processor type and the 16-bit disassembly mode.
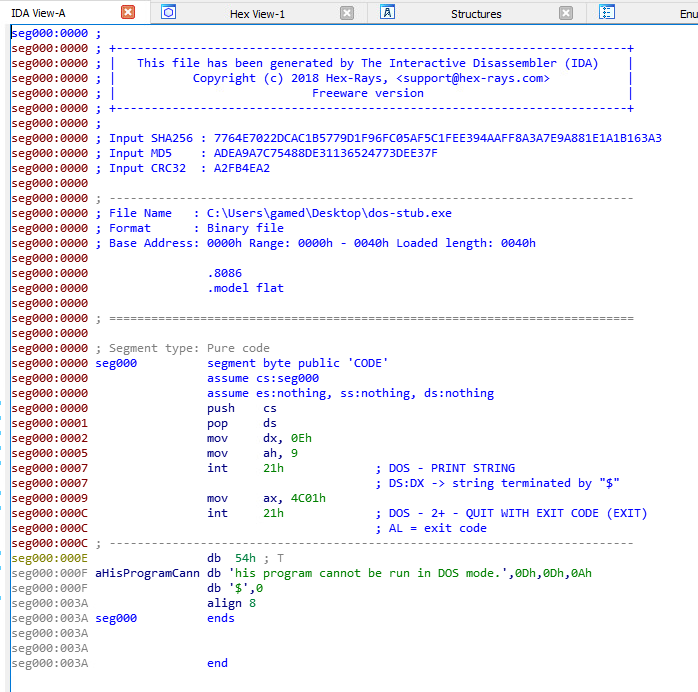
It’s a fairly simple program, let’s step through it line by line:
seg000:0000 push cs
seg000:0001 pop ds
First line pushes the value of cs onto the stack and the second line pops that value from the top of stack into ds. This is just a way of setting the value of the data segment to the same value as the code segment.
seg000:0002 mov dx, 0Eh
seg000:0005 mov ah, 9
seg000:0007 int 21h ; DOS - PRINT STRING
seg000:0007 ; DS:DX -> string terminated by "$"
These three lines are responsible for printing the error message, first line sets dx to the address of the string “This program cannot be run in DOS mode.” (0xe), second line sets ah to 9 and the last line invokes interrupt 21h.
Interrupt 21h is a DOS interrupt (API call) that can do a lot of things, it takes a parameter that determines what function to execute and that parameter is passed in the ah register.
We see here that the value 9 is given to the interrupt, 9 is the code of the function that prints a string to the screen, that function takes a parameter which is the address of the string to print, that parameter is passed in the dx register as we can see in the code.
Information about the DOS API can be found on wikipedia.
seg000:0009 mov ax, 4C01h
seg000:000C int 21h ; DOS - 2+ - QUIT WITH EXIT CODE (EXIT)
seg000:000C ; AL = exit code
The last three lines of the program are again an interrupt 21h call, this time there’s a mov instruction that puts 0X4C01 into ax, this sets al to 0x01 and ah to 0x4c.
0x4c is the function code of the function that exits with an error code, it takes the error code from al, which in this case is 1.
So in summary, all the DOS stub is doing is print the error message then exit with code 1.
Rich Header
So now we’ve seen the DOS Header and the DOS Stub, however there’s still a chunk of data we haven’t talked about lying between the DOS Stub and the start of the NT Headers.
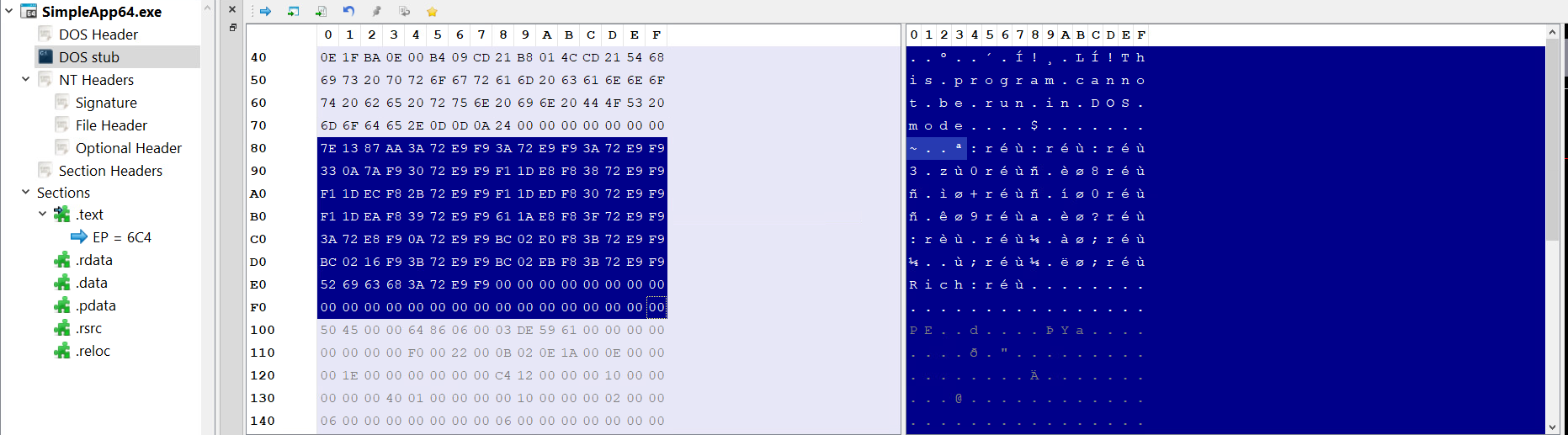
This chunk of data is commonly referred to as the Rich Header, it’s an undocumented structure that’s only present in executables built using the Microsoft Visual Studio toolset.
This structure holds some metadata about the tools used to build the executable like their names or types and their specific versions and build numbers.
All of the resources I have read about PE files didn’t mention this structure, however when searching about the Rich Header itself I found a decent amount of resources, and that makes sense because the Rich Header is not actually a part of the PE file format structure and can be completely zeroed-out without interfering with the executable’s functionality, it’s just something that Microsoft adds to any executable built using their Visual Studio toolset.
I only know about the Rich Header because I’ve read the reports on the Olympic Destroyer malware, and for those who don’t know what Olympic Destroyer is, it’s a malware that was written and used by a threat group in an attempt to disrupt the 2018 Winter Olympics.
This piece of malware is known for having a lot of false flags that were intentionally put to cause confusion and misattribution, one of the false flags present there was a Rich Header.
The authors of the malware overwrote the original Rich Header in the malware executable with the Rich Header of another malware attributed to the Lazarus threat group to make it look like it was Lazarus.
You can check Kaspersky’s report for more information about this.
The Rich Header consists of a chunk of XORed data followed by a signature (Rich) and a 32-bit checksum value that is the XOR key.
The encrypted data consists of a DWORD signature DanS, 3 zeroed-out DWORDs for padding, then pairs of DWORDS each pair representing an entry, and each entry holds a tool name, its build number and the number of times it’s been used.
In each DWORD pair the first pair holds the type ID or the product ID in the high WORD and the build ID in the low WORD, the second pair holds the use count.
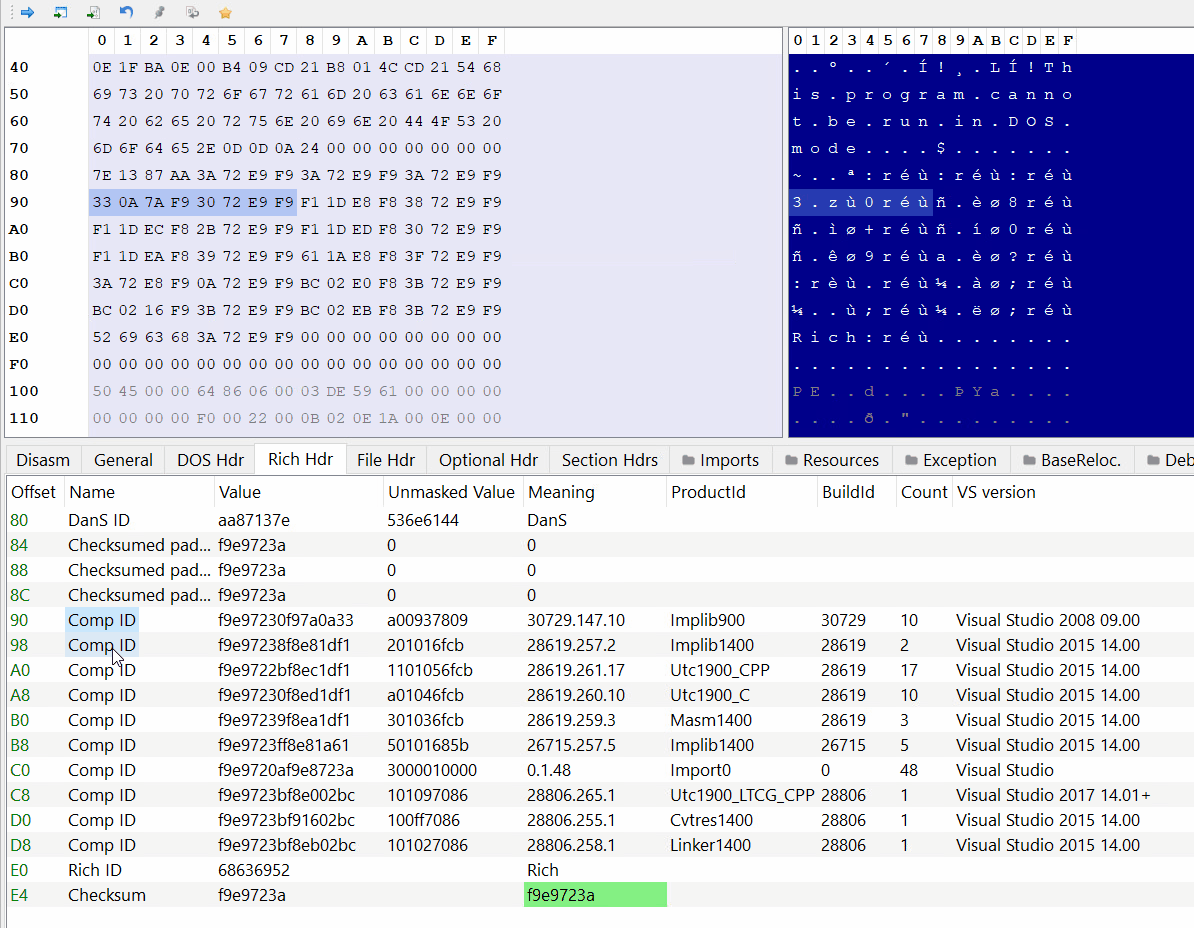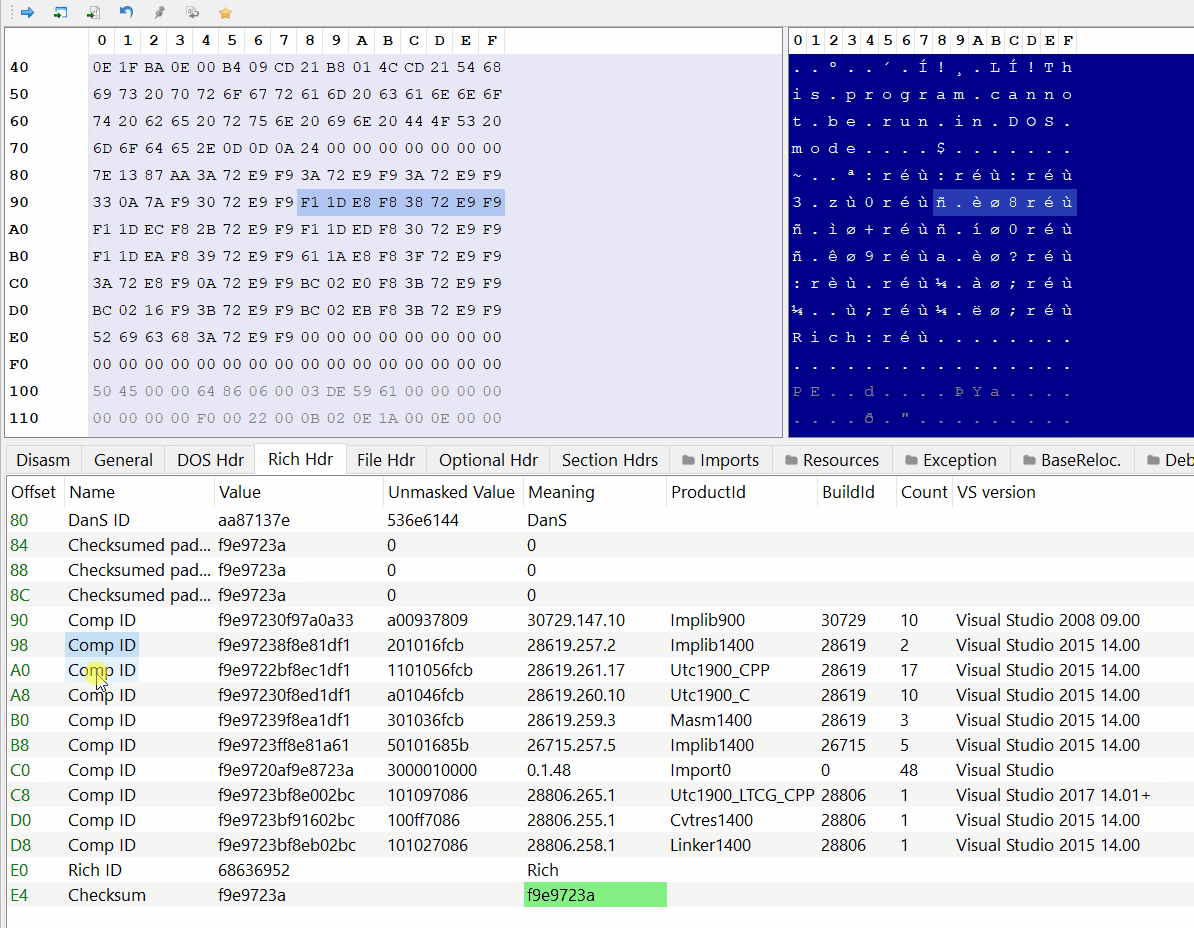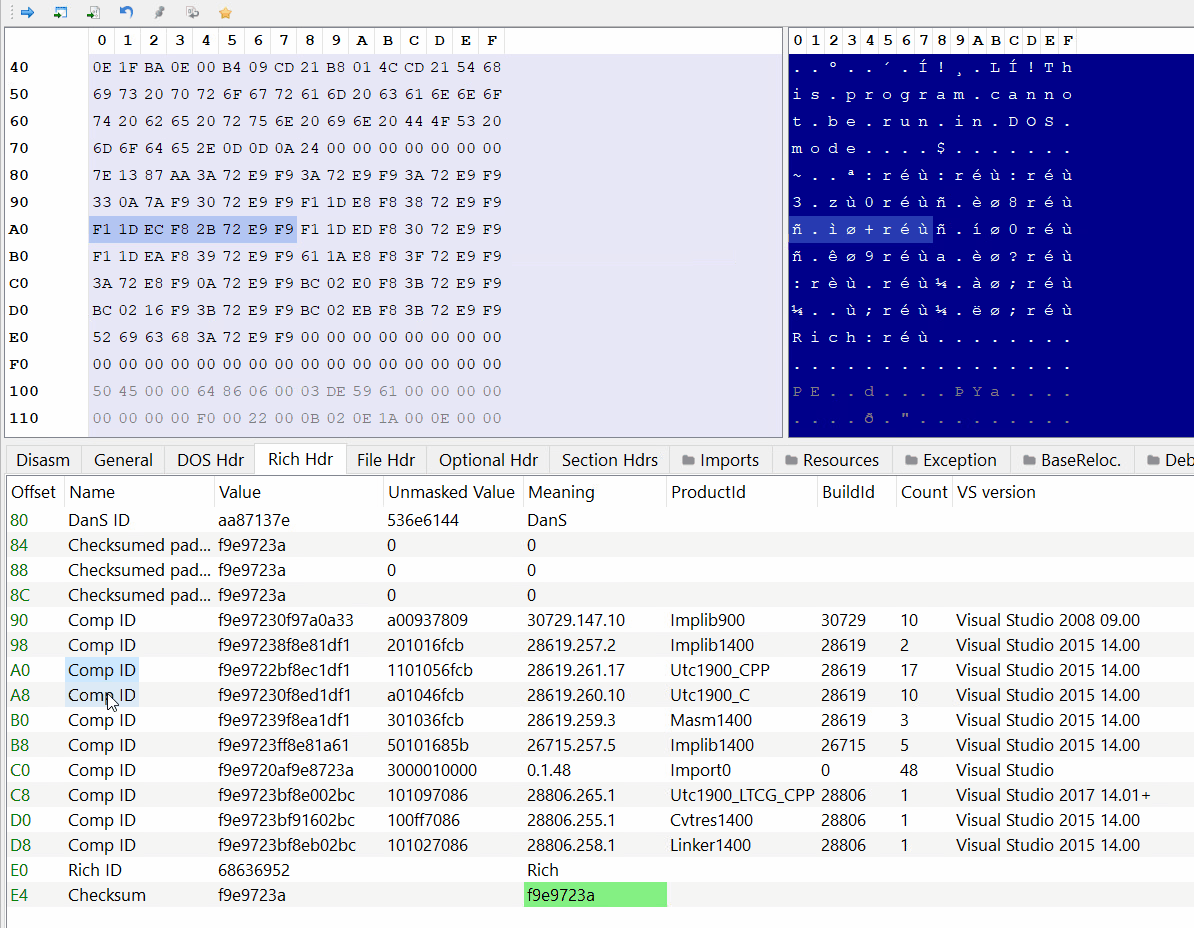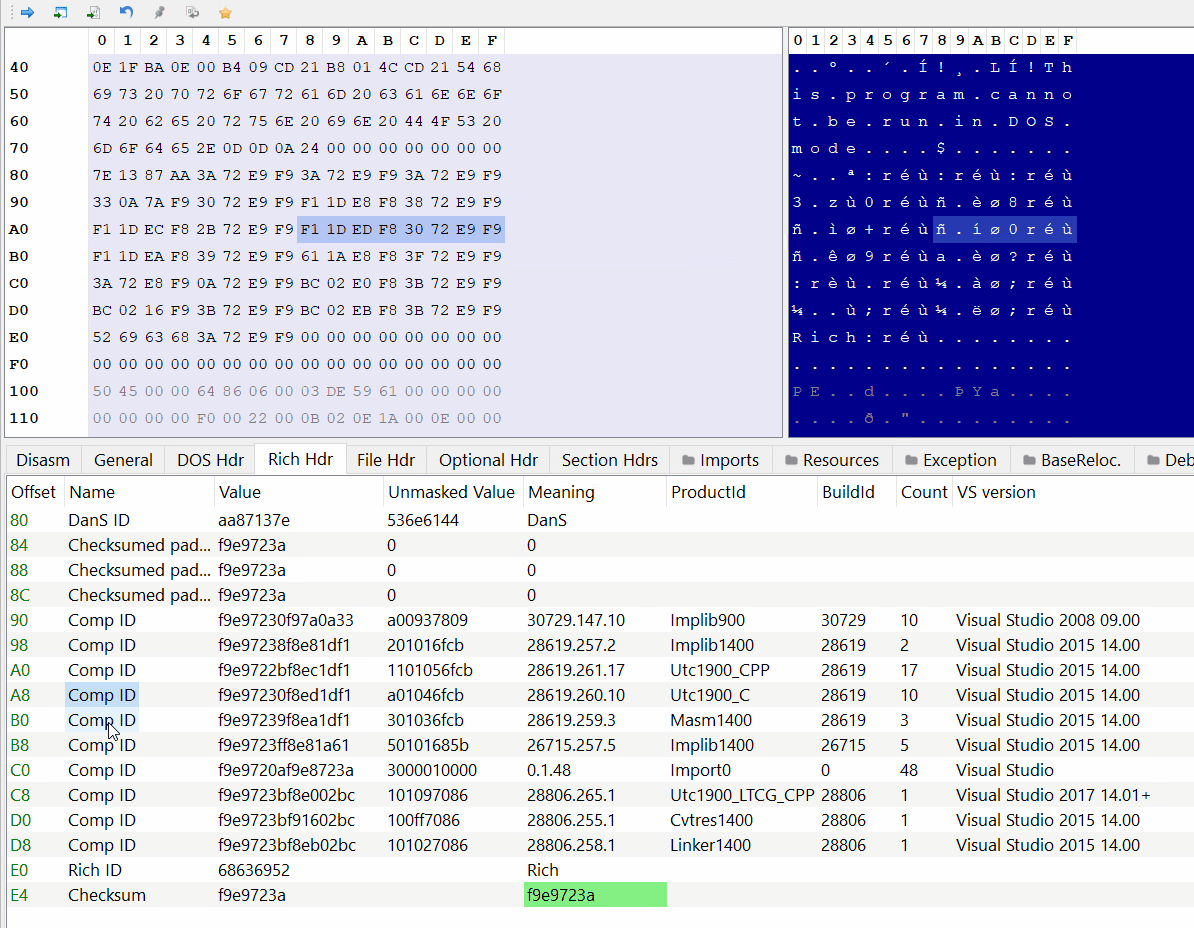
PE-bear parses the Rich Header automatically:
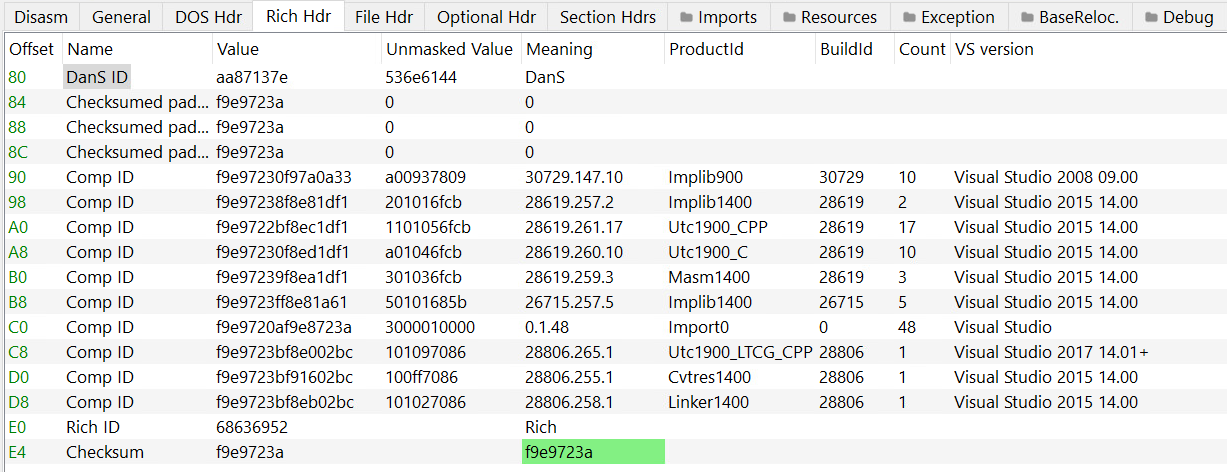
As you can see the DanS signature is the first thing in the structure, then there are 3 zeroed-out DWORDs and after that comes the entries.
We can also see the corresponding tools and Visual Studio versions of the product and build IDs.
As an exercise I wrote a script to parse this header myself, it’s a very simple process, all we need to do is to XOR the data, then read the entry pairs and translate them.
Rich Header data:
7E 13 87 AA 3A 72 E9 F9 3A 72 E9 F9 3A 72 E9 F9
33 0A 7A F9 30 72 E9 F9 F1 1D E8 F8 38 72 E9 F9
F1 1D EC F8 2B 72 E9 F9 F1 1D ED F8 30 72 E9 F9
F1 1D EA F8 39 72 E9 F9 61 1A E8 F8 3F 72 E9 F9
3A 72 E8 F9 0A 72 E9 F9 BC 02 E0 F8 3B 72 E9 F9
BC 02 16 F9 3B 72 E9 F9 BC 02 EB F8 3B 72 E9 F9
52 69 63 68 3A 72 E9 F9 00 00 00 00 00 00 00 00
Script:
import textwrap
def xor(data, key):
return bytearray( ((data[i] ^ key[i % len(key)]) for i in range(0, len(data))) )
def rev_endiannes(data):
tmp = [data[i:i+8] for i in range(0, len(data), 8)]
for i in range(len(tmp)):
tmp[i] = "".join(reversed([tmp[i][x:x+2] for x in range(0, len(tmp[i]), 2)]))
return "".join(tmp)
data = bytearray.fromhex("7E1387AA3A72E9F93A72E9F93A72E9F9330A7AF93072E9F9F11DE8F83872E9F9F11DECF82B72E9F9F11DEDF83072E9F9F11DEAF83972E9F9611AE8F83F72E9F93A72E8F90A72E9F9BC02E0F83B72E9F9BC0216F93B72E9F9BC02EBF83B72E9F9")
key = bytearray.fromhex("3A72E9F9")
rch_hdr = (xor(data,key)).hex()
rch_hdr = textwrap.wrap(rch_hdr, 16)
for i in range(2,len(rch_hdr)):
tmp = textwrap.wrap(rch_hdr[i], 8)
f1 = rev_endiannes(tmp[0])
f2 = rev_endiannes(tmp[1])
print("{} {} : {}.{}.{}".format(f1, f2, str(int(f1[4:],16)), str(int(f1[0:4],16)), str(int(f2,16)) ))
Please note that I had to reverse the byte-order because the data was presented in little-endian.
After running the script we can see an output that’s identical to PE-bear’s interpretation, meaning that the script works fine.
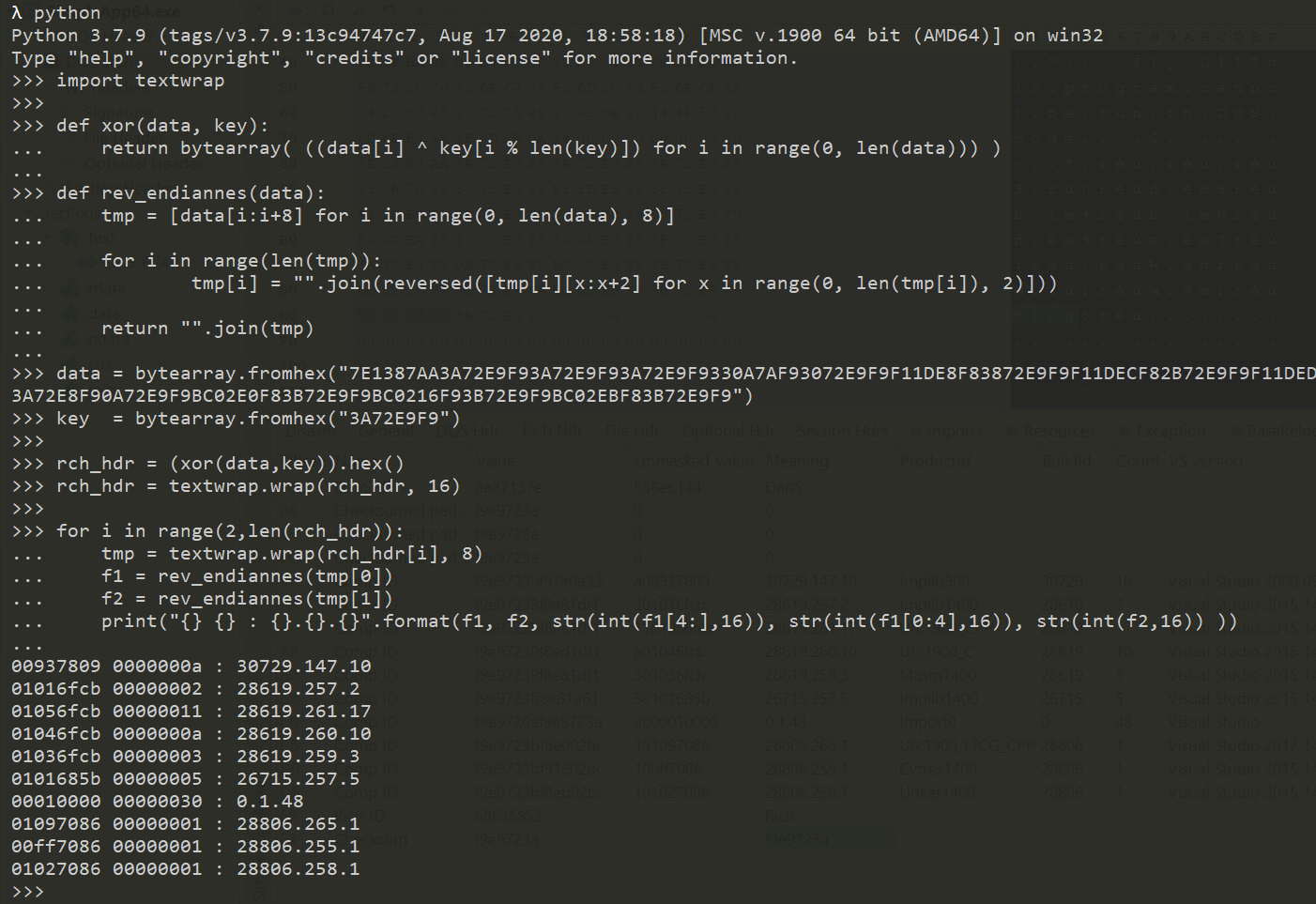
Translating these values into the actual tools types and versions is a matter of collecting the values from actual Visual Studio installations.
I checked the source code of bearparser (the parser used in PE-bear) and I found comments mentioning where these values were collected from.
//list from: https://github.com/kirschju/richheader
//list based on: https://github.com/kirschju/richheader + pnx's notes
You can check the source code for yourself, it’s on hasherezade’s (PE-bear author) Github page.
Conclusion
In this post we talked about the first two parts of the PE file, the DOS header and the DOS stub, we looked at the members of the DOS header structure and we reversed the DOS stub program.
We also looked at the Rich Header, a structure that’s not essentially a part of the PE file format but was worth checking.
The following image summarizes what we’ve talked about in this post:
