Binary Exploitation - Buffer Overflow Explained in Detail
Binary Exploitation - Buffer Overflow Explained in Detail
Introduction
First of all I’m writing this to help anyone who wants to learn about buffer overflow attacks, the basics to understand this can be confusing and it took me some time to understand it myself so I’ll be covering some basics in this article, what I’m going to talk about is what is a buffer , what is a stack and what are the memory addresses and we will take a look at the application memory structure , what is a buffer overflow and why does it happen then I’ll show a really basic and simple example for a buffer overflow (protostar stack0)

Buffer
So what’s a buffer ? Simply a buffer is a memory place or location which is used by a running program. This memory location is used to store some temporary data that is being used by the program. So for example if we have a simple program that asks the user to enter his name and stores it in a variable called username then it prints “Hello username “ . For example if we run the program and enter username as “Rick”. The word “Rick” is stored in the buffer until the program executes the print command and it retrieves the given username “Rick” from the buffer to output the result : “Hello Rick”
Our example written in c will be like this
#include <stdio.h>
int main () {
char username[20];
printf("Enter your name: ");
scanf("%s", username);
printf("Hello %s\n", username);
return(0);
}
Break Down :
int main() This defines the main function
char username[20] This is where we specify the variable name but the most important thing about this line is char .... [20] this is where we specify the buffer for that variable , and i assigned it as 20 chars
The rest of the code takes the user input then prints it.
printf("Enter your name: ");
scanf("%s", username);
printf("Hello %s\n, username");
So when we compile and run this program we get the output as expected right ?

Now before we talk about the buffer overflow we need to understand how the application memory works
Application Memory , Stack and Memory Addresses
So how does the application memory look like and what’s a stack ? A stack is a memory buffer that is used to store the functions of the program and local variables. To demonstrate this, we will take a look at this image.
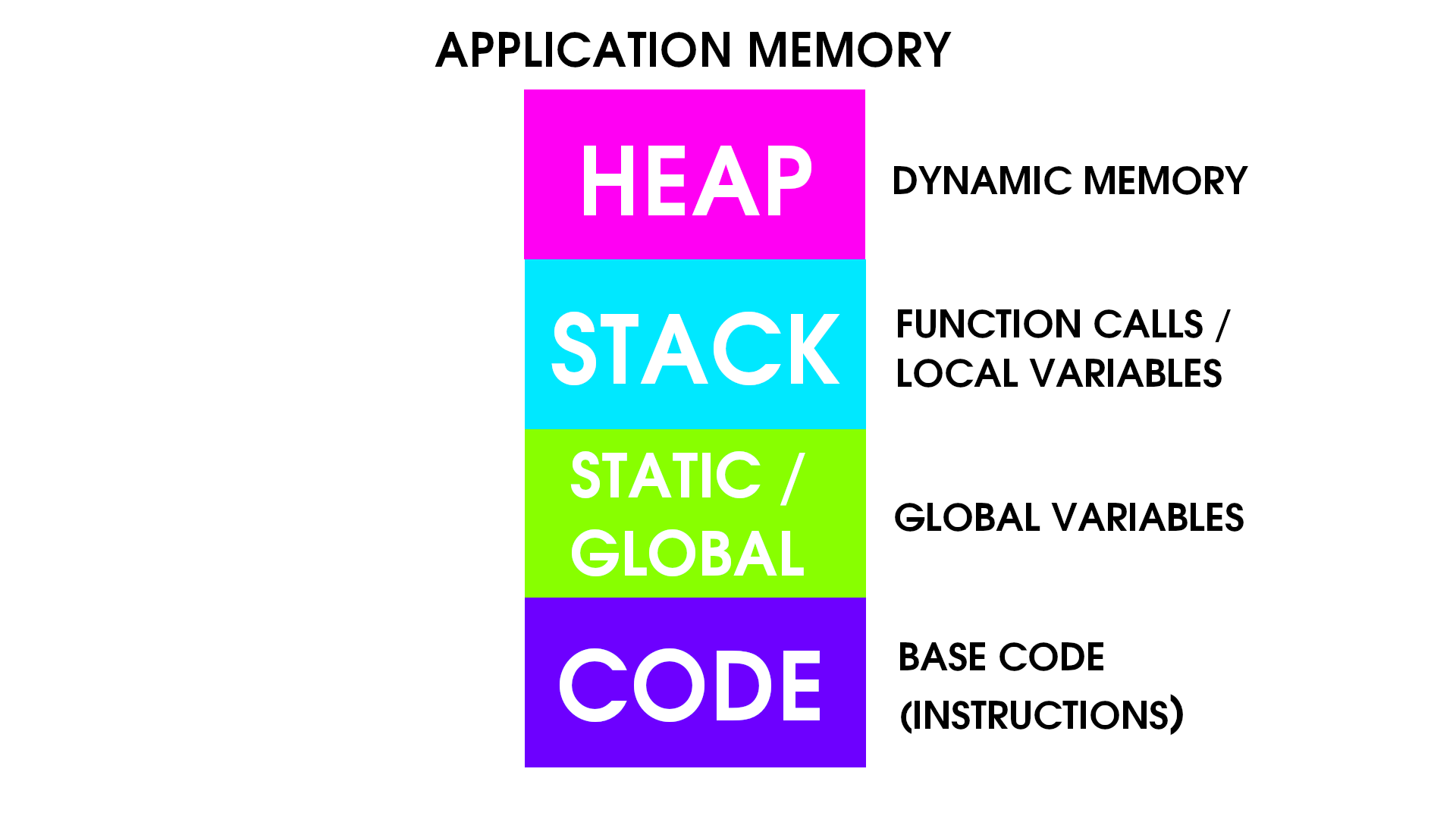
First We have the code and this is the source code of the program. This has the main instructions of the program.
After that we have the buffer where the global variables are stored,
The difference between a local variable and a global variable is that a local variable is limited to a certain function. It’s defined in that function and can be only called in that function but a global variable is either defined in the main function or defined outside a function and this type of variables can be called anywhere.
Then we have the Stack and this is the important part of the memory for us because this is where the buffer overflow happens. This is the place where local variable and function calls are stored.
Last thing is Heap and this is a dynamic memory allocation.
Now we know what does the application memory look like and what is the stack but what are memory addresses ?
Basically when a program is compiled and executed , All the instructions of the program take place in the application memory and an address is assigned to them , This address is usually in the format of hexadecimal bytes.
So if you disassemble a program and look at it you’ll find the memory addresses , something like this :
Why Do Buffer Overflows Happen ?
Now we know what is a buffer and we took a deeper look on the memory construction. Now you might already figured out why and when does a buffer overflow happen. A buffer overflow happens when the length of the data entered exceeds the buffer limit and this causes the program to write data outside the allocated buffer area and may overwrite some parts of the memory that were used to hold data used by the program which makes it unavailable and causes the program to crash. To demonstrate this we will go back to our first example.
#include <stdio.h>
int main () {
char username[20];
printf("Enter your name: ");
scanf("%s", username);
printf("Hello %s\n", username);
printf("Program exited normally");
return(0);
}
We will add a last line to print the sentence “program exited noramlly” just for demonstration purposes
Now the program should ask us for username then print “Hello username” then print “program exited normally” and exits. The buffer for holding the username value is set to 20 chars , it’s good as long as the username length is less than 20 chars. But if the entered data is more than 20 chars length the program will crash because some data will be overwritten outside the buffer causing some parts of the program to be corrupted. in our case this will be the part which prints “program exited normally”
First let’s run the program and enter the name as Rick

The program exits normally.
Now let’s run it again and enter the name as 30 A’s
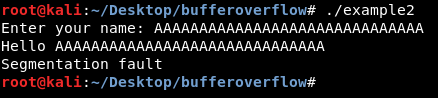
We get “Hello AAAAAAAAAAAAAAAAAAAAAAAAAAAAAA” printed then we don’t see “program exited normally” and we get a segmentation fault error. That happened because we entered 10 extra chars, The program only expected 20 or less. Those extra “AAAAAAAAAA” exceeded the 20 chars buffer and overwrited other data (The print instruction which prints “program exited normally”) which caused a segmentation fault because the program is corrupted.
Examining Buffer Overflows with gdb
Let’s take a deeper look at how this is happening with gdb (gnu debugger).
We will write another program that creates a variable called “whatever” then it copies what we give it and put it in that variable. And we will assign the buffer for that variable to be 20
#include <stdio.h>
#include <string.h>
int main(int argc, char** argv)
{
char whatever[20];
strcpy(whatever, argv[1]);
return 0;
}
Breakdown :
int main(int argc, char** argv) This defines the main function and it’s arguments
char whatever[20]; This creates the variable and gives it the name “whatever” and assigns its buffer to 20
strcpy(whatever, argv[1]); This copies our input and puts it into our variable “whatever”
Now let’s run the program inside gdb and test it.

The input was aaaaa which is less than 20 chars so the program exited normally and everything is good
Now let’s throw an input more that 20 chars.

We get a segmentation fault because our return address is overwritten and the program couldn’t continue.
To show how are these addresses overwritten let’s input any hex value , something like \x12 for 50 times. Then let’s look at the registers.
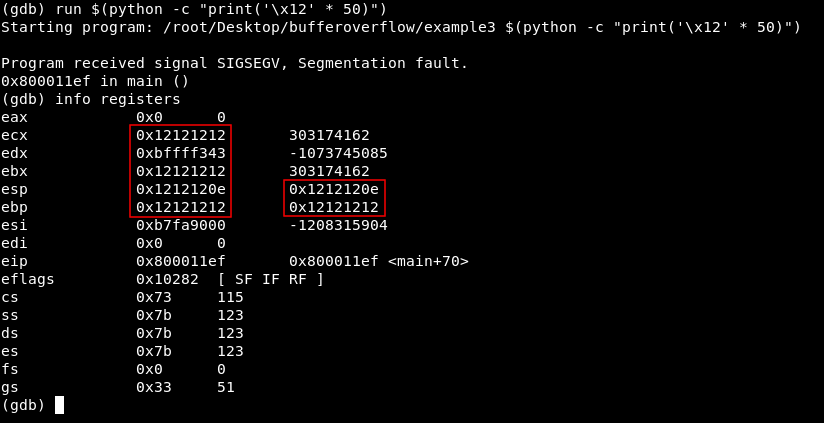
We see that most of the memory addresses are overwritten with 12
Why Are Buffer Overflows Dangerous ?
Now you might ask yourself , How will that be harmful ?
A buffer overflow is dangerous when the vulnerable binary or program is a setuid binary , If you don’t know what setuid binaries are, read the provided link, but in general They are programs that run with capabilities of another user (usually root) , But when that program is vulnerable to a buffer overflow it’s not a good thing anymore. Since we can pass the buffer and overwrite the program then we can overwrite it with a payload that executes a system call and spawns a root shell
I will do more write ups about buffer overflows and other binary exploitation techniques, for now I will start with protostar.
There are also some cool boxes on Hack The box that required buffer overflows and binary exploitation to gain root privileges but they’re active right now so I’ll publish my write ups about these boxes as soon as they retire of course. In the meantime, you can read my other Hack The Box write-ups !
Protostar Stack0
Now let’s do a simple practical example.
You can download protostar from here
I will solve the first level which is stack0 for this article then I will solve the rest of the levels in other write-ups.
We’re given the source code of the program :
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
int main(int argc, char **argv)
{
volatile int modified;
char buffer[64];
modified = 0;
gets(buffer);
if(modified != 0) {
printf("you have changed the 'modified' variable\n");
} else {
printf("Try again?\n");
}
}
From the code we can understand that the program has a variable called “buffer” and assigns a buffer of 64 chars to it. Then there’s another variable called modified and it’s value is 0. gets(buffer) allows us to input the value of “buffer” variable.Then there’s an if statement that checks if the value of “modified” variable is not equal to 0. If it’s not equal to zero it will print “you have changed the ‘modified’ variable” but if it’s still equal to 0 it will print “Try again?”. So our mission is to change the value of that variable called “modified”
As long as the entered data is less than 64 chars everything will run as intended. But if the input exceeds the buffer it will overwrite the value of “modified” variable.
We already know that the buffer is 64 chars so we just need to input 65 chars or more and the variable value will change. Let’s test that out.
We execute the stack0 bin and we see the output “try again?”

Let’s throw 65 “A”s and see the output.
python -c "print ('A' * 65)" | ./stack0

And we have successfuly overwritten the variable’s value ! :D
That’s it , Feedback is appreciated !
Don’t forget to read the previous articles , Tweet about the article if you liked it , follow on twitter @Ahm3d_H3sham
Thanks for reading.
Next Binary Exploitation article : Buffer Overflow Examples, Overwriting a variable value on the stack - Protostar Stack1 , Stack2